-- Query the right table in information_schema
SELECT table_name
FROM information_schema.tables
-- Specify the correct table_schema value
WHERE table_schema = 'public';| table_name |
|---|
| university_professors |
Short Description
Learn how to create tables and specify their relationships in SQL, as well as how to enforce data integrity and other unique features of database systems.
Long Description
You’ve already used SQL to query data from databases. But did you know that there’s a lot more you can do with databases? You can model different phenomena in your data, as well as the relationships between them. This gives your data structure and consistency, which results in better data quality. In this course, you’ll experience this firsthand by working with a real-life dataset that was used to investigate questionable university affiliations. Column by column, table by table, you’ll get to unlock and admire the full potential of databases. You’ll learn how to create tables and specify their relationships, as well as how to enforce data integrity. You’ll also discover other unique features of database systems, such as constraints.
In this chapter, you’ll create your very first database with a set of simple SQL commands. Next, you’ll migrate data from existing flat tables into that database. You’ll also learn how meta-information about a database can be queried.
Theory. Coming soon …
1. Your first database
Welcome to this course on Introduction to Relational Databases. My name is Timo Grossenbacher, and I work as a data journalist in Switzerland. In this course, you will see why using relational databases has many advantages over using flat files like CSVs or Excel sheets. You’ll learn how to create such databases, and bring into force their most prominent features.
2. Investigating universities in Switzerland
Let me tell you a little story first. As a data journalist, I try to uncover corruption, misconduct and other newsworthy stuff with data. A couple of years ago I researched secondary employment of Swiss university professors. It turns out a lot of them have more than one side job besides their university duty, being paid by big companies like banks and insurances. So I discovered more than 1500 external employments and visualized them in an interactive graphic, shown on the left. For this story, I had to compile data from various sources with varying quality. Also, I had to account for certain specialties, for example, that a professor can work for different universities; or that a third-party company can have multiple professors working for them. In order to analyze the data, I needed to make sure its quality was good and stayed good throughout the process. That’s why I stored my data in a database, whose quite complex design you can see in the right graphic. All these rectangles were turned into database tables.
3. A relational database:
But why did I use a database? A database models real-life entities like professors and universities by storing them in tables. Each table only contains data from a single entity type. This reduces redundancy by storing entities only once – for example, there only needs to be one row of data containing the details of a certain company. Lastly, a database can be used to model relationships between entities. You can define exactly how entities relate to each other. For instance, a professor can work at multiple universities and companies, while a company can employ more than one professor.
4. Throughout this course you will:
Throughout this course, you will actually work with the same real-life data used during my investigation. You’ll start from a single table of data and build a full-blown relational database from it, column by column, table by table. By doing so, you’ll get to know constraints, keys, and referential integrity. These three concepts help preserve data quality in databases. By the end of the course, you’ll know how to use them. In order to get going, you’ll just need a basic understanding of SQL – which can also be used to build and maintain databases, not just for querying data.
5. Your first duty: Have a look at the PostgreSQL database
I’ve already created a single PostgreSQL database table containing all the raw data for this course. In the next few exercises, I want you to have a look at that table. For that, you’ll need to retrieve your SQL knowledge and query the “information_schema” database, which is available in PostgreSQL by default. “information_schema” is actually some sort of meta-database that holds information about your current database. It’s not PostgreSQL specific and also available in other database management systems like MySQL or SQL Server. This “information_schema” database holds various information in different tables, for example in the “tables” table.
6. Have a look at the columns of a certain table
“information_schema” also holds information about columns in the “columns” table. Once you know the name of a table, you can query its columns by accessing the “columns” table. Here, for example, you see that the system table “pg_config” has only two columns – supposedly for storing name-value pairs.
7. Let’s do this.
Okay, let’s have a look at your first database.
1.3 Question
Which of the following statements does not hold true for databases? Relational databases …
⬜ … store different real-world entities in different tables.
⬜ … allow to establish relationships between entities.
✅ … are called “relational” because they store data only about people.
⬜ … use constraints, keys and referential integrity in order to assure data quality.
Correct! Of course, databases can also store information about any other kind of entities, e.g. spare car parts.
information_schema is a meta-database that holds information about your current database. information_schema has multiple tables you can query with the known SELECT * FROM syntax:
tables: information about all tables in your current databasecolumns: information about all columns in all of the tables in your current databaseIn this exercise, you’ll only need information from the 'public' schema, which is specified as the column table_schema of the tables and columns tables. The 'public' schema holds information about user-defined tables and databases. The other types of table_schema hold system information – for this course, you’re only interested in user-defined stuff.
Steps
'public' table_schema.-- Query the right table in information_schema
SELECT table_name
FROM information_schema.tables
-- Specify the correct table_schema value
WHERE table_schema = 'public';| table_name |
|---|
| university_professors |
university_professors by selecting all entries in information_schema.columns that correspond to that table.-- Query the right table in information_schema to get columns
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_name = 'university_professors' AND table_schema = 'public';| column_name | data_type |
|---|---|
| firstname | text |
| lastname | text |
| university | text |
| university_shortname | text |
| university_city | text |
| function | text |
| organization | text |
| organization_sector | text |
1.5 Question
How many columns does the table
university_professorshave?
⬜ 12
⬜ 9
✅ 8
⬜ 5
university_professors table.| firstname | lastname | university | university_shortname | university_city | function | organization | organization_sector |
|---|---|---|---|---|---|---|---|
| Karl | Aberer | ETH Lausanne | EPF | Lausanne | Chairman of L3S Advisory Board | L3S Advisory Board | Education & research |
| Karl | Aberer | ETH Lausanne | EPF | Lausanne | Member Conseil of Zeno-Karl Schindler Foundation | Zeno-Karl Schindler Foundation | Education & research |
| Karl | Aberer | ETH Lausanne | EPF | Lausanne | Member of Conseil Fondation IDIAP | Fondation IDIAP | Education & research |
| Karl | Aberer | ETH Lausanne | EPF | Lausanne | Panel Member | SNF Ambizione Program | Education & research |
| Reza Shokrollah | Abhari | ETH Zürich | ETH | Zurich | Aufsichtsratsmandat | PNE Wind AG | Energy, environment & mobility |
Great work! You’re now familiar with the pre-existing university_professors table, which holds information on all kinds of entities. You’ll migrate data from this table to other tables in the upcoming lessons.
Theory. Coming soon …
1. Tables: At the core of every database
Now that you’ve had a first look at your database, let’s delve into one of the most important concepts behind databases: tables.
2. Redundancy in the university_professors table
You might have noticed that there’s some redundancy in the “university_professors” table. Let’s have a look at the first three records, for example.
3. Redundancy in the university_professors table
As you can see, this professor is repeated in the first three records. Also, his university, the “ETH Lausanne”, is repeated a couple of times – because he only works for this university. However, he seems to have affiliations with at least three different organizations. So, there’s a certain redundancy in that table. The reason for this is that the table actually contains entities of at least three different types. Let’s have a look at these entity types.
4. Redundancy in the university_professors table
Actually the table stores professors, highlighted in blue, universities, highlighted in green, and organizations, highlighted in brown. There’s also this column called “function” which denotes the role the professor plays at a certain organization. More on that later.
5. Currently: One “entity type” in the database
Let’s look at the current database once again. The graphic used here is called an entity-relationship diagram. Squares denote so-called entity types, while circles connected to these denote attributes (or columns). So far, we have only modeled one so-called entity type – “university_professors”. However, we discovered that this table actually holds many different entity types…
6. A better database model with three entity types
…so this updated entity-relationship model on the right side would be better suited. It represents three entity types, “professors”, “universities”, and “organizations” in their own tables, with respective attributes. This reduces redundancy, as professors, unlike now, need to be stored only once. Note that, for each professor, the respective university is also denoted through the “university_shortname” attribute. However, one original attribute, the “function”, is still missing.
7. A better database model with four entity types
As you know, this database contains affiliations of professors with third-party organizations. The attribute “function” gives some extra information to that affiliation. For instance, somebody might act as chairman for a certain third-party organization. So the best idea at the moment is to store these affiliations in their own table – it connects professors with their respective organizations, where they have a certain function.
8. Create new tables with CREATE TABLE
The first thing you need to do now is to create four empty tables for professors, universities, organizations, and affiliations. This is quite easy with SQL – you’ll use the “CREATE TABLE” command for that. At the minimum, this command requires a table name and one or more columns with their respective data types.
9. Create new tables with CREATE TABLE
For example, you could create a “weather” table with three aptly named columns. After each column name, you must specify the data type. There are many different types, and you will discover some in the remainder of this course. For example, you could specify a text column, a numeric column, and a column that requires fixed-length character strings with 5 characters each. These data types will be explained in more detail in the next chapter.
10. Let’s practice!
For now, you will first create the four tables and then migrate data from the original table to them. Let’s do this.
You’ll now start implementing a better database model. For this, you’ll create tables for the professors and universities entity types. The other tables will be created for you.
The syntax for creating simple tables is as follows:
Attention: Table and columns names, as well as data types, don’t need to be surrounded by quotation marks.
Steps
professors with two text columns: firstname and lastname.universities with three text columns: university_shortname, university, and university_city.| university_shortname | university | university_city |
|---|
Great job. The other two tables, affiliations and organizations, will be created for you.
Oops! We forgot to add the university_shortname column to the professors table. You’ve probably already noticed:
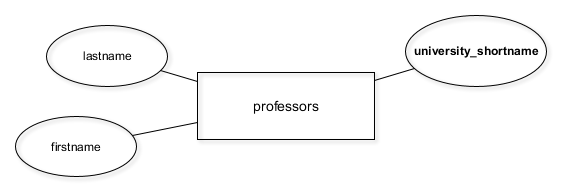
In chapter 4 of this course, you’ll need this column for connecting the professors table with the universities table.
However, adding columns to existing tables is easy, especially if they’re still empty.
To add columns you can use the following SQL query:
Steps
professors to add the text column university_shortname.| firstname | lastname | university_shortname |
|---|
Perfect – now your first sample database model is complete. Time to fill these tables with data!
Theory. Coming soon …
1. Update your database as the structure changes
Well done so far. You now have a database consisting of five different tables. Now it’s time to migrate the data.
2. The current database model
Here’s the current entity-relationship diagram, showing the five tables.
3. The current database model
At this moment, only the “university_professors” table holds data. The other four, shown in red, are still empty. In the remainder of this chapter, you will migrate data from the green part of this diagram to the red part, moving the respective entity types to their appropriate tables. In the end, you’ll be able to delete the “university_professors” table.
4. Only store DISTINCT data in the new tables
One advantage of splitting up “university_professors” into several tables is the reduced redundancy. As of now, “university_professors” holds 1377 entries. However, there are only 1287 distinct organizations, as this query shows. Therefore, you only need to store 1287 distinct organizations in the new “organizations” table.
5. INSERT DISTINCT records INTO the new tables
In order to copy data from an existing table to a new one, you can use the “INSERT INTO SELECT DISTINCT” pattern. After “INSERT INTO”, you specify the name of the target table – “organizations” in this case. Then you select the columns that should be copied over from the source table – “unviversity_professors” in this case. You use the “DISTINCT” keyword to only copy over distinct organizations. As the output shows, only 1287 records are inserted into the “organizations” table. If you just used “INSERT INTO SELECT”, without the “DISTINCT” keyword, duplicate records would be copied over as well. In the following exercises, you will migrate your data to the four new tables.
6. The INSERT INTO statement
By the way, this is the normal use case for “INSERT INTO” – where you insert values manually. “INSERT INTO” is followed by the table name and an optional list of columns which should be filled with data. Then follows the “VALUES” keyword and the actual values you want to insert.
7. RENAME a COLUMN in affiliations
Before you start migrating the table, you need to fix some stuff! In the last lesson, I created the “affiliations” table for you. Unfortunately, I made a mistake in this process. Can you spot it? The way the “organisation” column is spelled is not consistent with the American-style spelling of this table, using an “s” instead of a “z”. In the first exercise after the video, you will correct this with the known “ALTER TABLE” syntax. You do this with the RENAME COLUMN command by specifying the old column name first and then the new column name, i.e., “RENAME COLUMN old_name TO new_name”.
8. DROP a COLUMN in affiliations
Also, the “university_shortname” column is not even needed here. So I want you to delete it. The syntax for this is again very simple, you use a “DROP COLUMN” command followed by the name of the column. Dropping columns is straightforward when the tables are still empty, so it’s not too late to fix this error. But why is it an error in the first place?
9. A professor is uniquely identified by firstname, lastname only
Well, I queried the “university_professors” table and saw that there are 551 unique combinations of first names, last names, and associated universities. I then queried the table again and only looked for unique combinations of first and last names. Turns out, this is also 551 records. This means that the columns “firstname” and “lastname” uniquely identify a professor.
10. A professor is uniquely identified by firstname, lastname only
So the “university_shortname” column is not needed in order to reference a professor in the affiliations table. You can remove it, and this will reduce the redundancy in your database again. In other words: The columns “firstname”, “lastname”, “function”, and “organization” are enough to store the affiliation a professor has with a certain organization.
11. Let’s get to work!
Time to prepare the database for data migration. After this, you will migrate the data.
As mentioned in the video, the still empty affiliations table has some flaws. In this exercise, you’ll correct them as outlined in the video.
You’ll use the following queries:
Steps
organisation column to organization in affiliations.university_shortname column in affiliations.Great work! Now the tables are finally ready for data migration.
Now it’s finally time to migrate the data into the new tables. You’ll use the following pattern:
It can be broken up into two parts:
First part:
This selects all distinct values in table table_a – nothing new for you.
Second part:
Take this part and append it to the first, so it inserts all distinct rows from table_a into table_b.
One last thing: It is important that you run all of the code at the same time once you have filled out the blanks.
Steps
DISTINCT professors from university_professors into professors.professors.| firstname | lastname | university_shortname |
|---|---|---|
| Michel | Rappaz | EPF |
| Hilal | Lashuel | EPF |
| Jeffrey | Huang | EPF |
| Pierre | Magistretti | EPF |
| Paolo | Ienne | EPF |
| Frédéric | Kaplan | EPF |
| Olivier | Hari | UNE |
| Christian | Hesse | UBE |
| Majed | Chergui | EPF |
| Douglas | Hanahan | EPF |
DISTINCT affiliations into affiliations from university_professors.| firstname | lastname | function | organization |
|---|---|---|---|
| Dimos | Poulikakos | VR-Mandat | Scrona AG |
| Francesco | Stellacci | Co-editor in Chief, Nanoscale | Royal Chemistry Society, UK |
| Alexander | Fust | Fachexperte und Coach für Designer Startups | Creative Hub |
| Jürgen | Brugger | Proposal reviewing HEPIA | HES Campus Biotech, Genève |
| Hervé | Bourlard | Director | Idiap Research Institute |
| Ioannis | Papadopoulos | Mandat | Schweizerischer Nationalfonds (SNF) |
| Olaf | Blanke | Professeur à 20% | Université de Genève |
| Leo | Staub | Präsident Verwaltungsrat | Genossenschaft Migros Ostschweiz |
| Pascal | Pichonnaz | Vize-Präsident | EKK (Eidgenössische Konsumenten Kommission) |
| Dietmar | Grichnik | Präsident | Swiss Startup Monitor Stiftung |
Perfect. You can see that there are 1377 distinct combinations of professors and organisations in the dataset. We’ll migrate the other two tables universities and organisations for you.
Migrate data to the universities and organizations tables
| university_shortname | university | university_city |
|---|---|---|
| UGE | Uni Genf | Geneva |
| USI | USI Lugano | Lugano |
| UFR | Uni Freiburg | Fribourg |
| USG | Uni St. Gallen | Saint Gallen |
| ULA | Uni Lausanne | Lausanne |
| EPF | ETH Lausanne | Lausanne |
| UBE | Uni Bern | Bern |
| ETH | ETH Zürich | Zurich |
| UNE | Uni Neuenburg | Neuchâtel |
| UBA | Uni Basel | Basel |
| organization | organization_sector |
|---|---|
| Stiftung-Sammlung Schweizer Rechtsquellen | Not classifiable |
| ResponsAbility | Financial industry & insurances |
| Fondation IQRGC | Not classifiable |
| u-blox AG | Industry, construction & agriculture |
| Departement für Entwicklungshilfe und -zusammenarbeit DEZA | Politics, administration, justice system & security sector |
| ub-invent GmbH | Pharma & health |
| Quiartet Medicine, Boston, USA | Technology |
| CSSI Bern | Politics, administration, justice system & security sector |
| Schweizerische Akademie der Naturwissenschaften SCNAT Bern | Education & research |
| Avenir Suisse | Society, Social, Culture & Sports |
The last thing to do in this chapter is to delete the no longer needed university_professors table.
Obviously, the university_professors table is now no longer needed and can safely be deleted.
For table deletion, you can use the simple command:
Steps
university_professors table.Perfect! Now it’s finally time to delve into the real advantages of databases. In the following chapters, you will discover many cool features that ultimately lead to better data consistency and quality, such as domain constraints, keys, and referential integrity. See you soon!
After building a simple database, it’s now time to make use of the features. You’ll specify data types in columns, enforce column uniqueness, and disallow NULL values in this chapter.
Theory. Coming soon …
1. Better data quality with constraints
So far you’ve learned how to set up a simple database that consists of multiple tables. Apart from storing different entity types, such as professors, in different tables, you haven’t made much use of database features. In the end, the idea of a database is to push data into a certain structure – a pre-defined model, where you enforce data types, relationships, and other rules. Generally, these rules are called integrity constraints, although different names exist.
2. Integrity constraints
Integrity constraints can roughly be divided into three types. The most simple ones are probably the so-called attribute constraints. For example, a certain attribute, represented through a database column, could have the integer data type, allowing only for integers to be stored in this column. They’ll be the subject of this chapter. Secondly, there are so-called key constraints. Primary keys, for example, uniquely identify each record, or row, of a database table. They’ll be discussed in the next chapter. Lastly, there are referential integrity constraints. In short, they glue different database tables together. You’ll learn about them in the last chapter of this course.
3. Why constraints?
So why should you know about constraints? Well, they press the data into a certain form. With good constraints in place, people who type in birthdates, for example, have to enter them in always the same form. Data entered by humans is often very tedious to pre-process. So constraints give you consistency, meaning that a row in a certain table has exactly the same form as the next row, and so forth. All in all, they help to solve a lot of data quality issues. While enforcing constraints on human-entered data is difficult and tedious, database management systems can be a great help. In the next chapters and exercises, you’ll explore how.
4. Data types as attribute constraints
You’ll start with attribute constraints in this chapter. In its simplest form, attribute constraints are data types that can be specified for each column of a table. Here you see the beginning of a list of all data types in PostgreSQL. There are basic data types for numbers, such as “bigint”, or strings of characters, such as “character varying”. There are also more high-level data types like “cidr”, which can be used for IP addresses. Implementing such a type on a column would disallow anything that doesn’t fit the structure of an IP.
5. Dealing with data types (casting)
Data types also restrict possible SQL operations on the stored data. For example, it is impossible to calculate a product from an integer and a text column, as shown here in the example. The text column “wind_speed” may store numbers, but PostgreSQL doesn’t know how to use text in a calculation. The solution for this is type casts, that is, on-the-fly type conversions. In this case, you can use the “CAST” function, followed by the column name, the AS keyword, and the desired data type, and PostgreSQL will turn “wind_speed” into an integer right before the calculation.
6. Let’s practice!
Okay, let’s look into this first type of constraints!
2.3 Question
Which of the following is not used to enforce a database constraint?
⬜ Foreign keys
✅ SQL aggregate functions
⬜ The BIGINT data type
⬜ Primary keys
Exactly! SQL aggregate functions are not used to enforce constraints, but to do calculations on data.
For demonstration purposes, I created a fictional database table that only holds three records. The columns have the data types date, integer, and text, respectively.
Have a look at the contents of the transactions table.
The transaction_date accepts date values. According to the PostgreSQL documentation, it accepts values in the form of YYYY-MM-DD, DD/MM/YY, and so forth.
Both columns amount and fee appear to be numeric, however, the latter is modeled as text – which you will account for in the next exercise.
Steps
-- Let's add a record to the table
INSERT INTO transactions (transaction_date, amount, fee)
VALUES ('2018-24-09', 5454, '30');#> Error: Failed to prepare query : ERROR: date/time field value out of range: "2018-24-09"
#> LINE 3: VALUES ('2018-24-09', 5454, '30');
#> ^
#> HINT: Perhaps you need a different "datestyle" setting.| transaction_date | amount | fee |
|---|---|---|
| 1999-01-08 | 500 | 20 |
| 2001-02-20 | 403 | 15 |
| 2001-03-20 | 3430 | 35 |
| 2018-09-24 | 5454 | 30 |
| 1999-01-08 | 500 | 20 |
| 2001-02-20 | 403 | 15 |
| 2001-03-20 | 3430 | 35 |
| 2018-09-24 | 5454 | 30 |
| 1999-01-08 | 500 | 20 |
| 2001-02-20 | 403 | 15 |
Good work. You can see that data types provide certain restrictions on how data can be entered into a table. This may be tedious at the moment of insertion, but saves a lot of headache in the long run.
In the video, you saw that type casts are a possible solution for data type issues. If you know that a certain column stores numbers as text, you can cast the column to a numeric form, i.e. to integer.
Now, the some_column column is temporarily represented as integer instead of text, meaning that you can perform numeric calculations on the column.
Steps
integer type cast at the right place and execute it again.-- Calculate the net amount as amount + fee
SELECT transaction_date, amount + fee AS net_amount
FROM transactions;#> Error: Failed to prepare query : ERROR: operator does not exist: double precision + text
#> LINE 2: SELECT transaction_date, amount + fee AS net_amount
#> ^
#> HINT: No operator matches the given name and argument types. You might need to add explicit type casts.-- Calculate the net amount as amount + fee
SELECT transaction_date, amount + CAST(fee AS integer) AS net_amount
FROM transactions;| transaction_date | net_amount |
|---|---|
| 1999-01-08 | 520 |
| 2001-02-20 | 418 |
| 2001-03-20 | 3465 |
| 2018-09-24 | 5484 |
| 1999-01-08 | 520 |
| 2001-02-20 | 418 |
| 2001-03-20 | 3465 |
| 2018-09-24 | 5484 |
| 1999-01-08 | 520 |
| 2001-02-20 | 418 |
Good job! You saw how, sometimes, type casts are necessary to work with data. However, it is better to store columns in the right data type from the first place. You’ll learn how to do this in the next exercises.
Theory. Coming soon …
1. Working with data types
Working with data types is straightforward in a database management system like PostgreSQL.
2. Working with data types
As said before, data types are attribute constraints and are therefore implemented for single columns of a table. They define the so-called “domain” of values in a column, that means, what form these values can take – and what not. Therefore, they also define what operations are possible with the values in the column, as you saw in the previous exercises. Of course, through this, consistent storage is enforced, so a street number will always be an actual number, and a postal code will always have no more than 6 digits, according to your conventions. This greatly helps with data quality.
3. The most common types
Here are the most common types in PostgreSQL. Note that these types are specific to PostgreSQL but appear in many other database management systems as well, and they mostly conform to the SQL standard. The “text” type allows characters strings of any length, while the “varchar” and “char” types specify a maximum number of characters, or a character string of fixed length, respectively. You’ll use these two for your database. The “boolean” type allows for two boolean values, for example, “true” and “false” or “1” and “0”, and for a third unknown value, expressed through “NULL”.
4. The most common types (cont’d.)
Then there are various formats for date and time calculations, also with timezone support. “numeric” is a general type for any sort of numbers with arbitrary precision, while “integer” allows only whole numbers in a certain range. If that range is not enough for your numbers, there’s also “bigint” for larger numbers.
5. Specifying types upon table creation
Here’s an example of how types are specified upon table creation. Let’s say the social security number, “ssn”, should be stored as an integer as it only contains whole numbers. The name may be a string with a maximum of 64 characters, which might or might not be enough. The date of birth, “dob”, is naturally stored as a date, while the average grade is a numeric value with a precision of 3 and a scale of 2, meaning that numbers with a total of three digits and two digits after the fractional point are allowed. Lastly, the information whether the tuition of the student was paid is, of course, a boolean one, as it can be either true or false.
6. Alter types after table creation
Altering types after table creation is also straightforward, just use the shown “ALTER TABLE ALTER COLUMN” statement. In this case, the maximum name length is extended to 128 characters.Sometimes it may be necessary to truncate column values or transform them in any other way, so they fit with the new data type. Then you can use the “USING” keyword, and specify a transformation that should happen before the type is altered. Let’s say you’d want to turn the “average_grade” column into an integer type. Normally, PostgreSQL would just keep the part of the number before the fractional point. With “USING”, you can tell it to round the number to the nearest integer, for example.
7. Let’s apply this!
Let’s apply this to your database and add the proper types to your table columns.
The syntax for changing the data type of a column is straightforward. The following code changes the data type of the column_name column in table_name to varchar(10):
Now it’s time to start adding constraints to your database.
Steps 1. Have a look at the distinct university_shortname values in the professors table and take note of the length of the strings.
| university_shortname |
|---|
| ULA |
| UNE |
| EPF |
| USG |
| UBA |
| UBE |
| UZH |
| UGE |
| UFR |
| USI |
university_shortname.firstname column to varchar(64).Good work. I’ve specified the types of the other tables for you.
If you don’t want to reserve too much space for a certain varchar column, you can truncate the values before converting its type.
For this, you can use the following syntax:
You should read it like this: Because you want to reserve only x characters for column_name, you have to retain a SUBSTRING of every value, i.e. the first x characters of it, and throw away the rest. This way, the values will fit the varchar(x) requirement.
Steps
SUBSTRING() to reduce firstname to 16 characters so its type can be altered to varchar(16).Perfect! However, it’s best not to truncate any values in your database, so we’ll revert this column to varchar(64). Now it’s time to move on to the next set of attribute constraints!
Theory. Coming soon …
1. The not-null and unique constraints
In the last part of this chapter, you’ll get to know two special attribute constraints: the not-null and unique constraints.
2. The not-null constraint
As the name already says, the not-null constraint disallows any “NULL” values on a given column. This must hold true for the existing state of the database, but also for any future state. Therefore, you can only specify a not-null constraint on a column that doesn’t hold any “NULL” values yet. And: It won’t be possible to insert “NULL” values in the future.
3. What does NULL mean?
Before I go on explaining how to specify not-null constraints, I want you to think about “NULL” values. What do they actually mean to you? There’s no clear definition. “NULL” can mean a couple of things, for example, that the value is unknown, or does not exist at all. It can also be possible that a value does not apply to the column. Let’s look into an example.
4. What does NULL mean? An example
Let’s say we define a table “students”. The first two columns for the social security number and the last name cannot be “NULL”, which makes sense: this should be known and apply to every student. The “home_phone” and “office_phone” columns though should allow for null values – which is the default, by the way. Why? First of all, these numbers can be unknown, for any reason, or simply not exist, because a student might not have a phone. Also, some values just don’t apply: Some students might not have an office, so they don’t have an office phone, and so forth. So, one important take away is that two “NULL” values must not have the same meaning. This also means that comparing “NULL” with “NULL” always results in a “FALSE” value.
5. How to add or remove a not-null constraint
You’ve just seen how to add a not-null constraint to certain columns when creating a table. Just add “not null” after the respective columns. But you can also add and remove not-null constraints to and from existing tables. To add a not-null constraint to an existing table, you can use the “ALTER COLUMN SET NOT NULL” syntax as shown here. Similarly, to remove a not-null constraint, you can use “ALTER COLUMN DROP NOT NULL”.
6. The unique constraint
The unique constraint on a column makes sure that there are no duplicates in a column. So any given value in a column can only exist once. This, for example, makes sense for university short names, as storing universities more than once leads to unnecessary redundancy. However, it doesn’t make sense for university cities, as two universities can co-exist in the same city. Just as with the not-null constraint, you can only add a unique constraint if the column doesn’t hold any duplicates before you apply it.
7. Adding unique constraints
Here’s how to create columns with unique constraints. Just add the “UNIQUE” keyword after the respective table column. You can also add a unique constraint to an existing table. For that, you have to use the “ADD CONSTRAINT” syntax. This is different from adding a “NOT NULL” constraint. However, it’s a pattern that frequently occurs. You’ll see plenty of other examples of “ADD CONSTRAINT” in the remainder of this course.
8. Let’s apply this to the database!
Okay, time now to apply the not-null and unique constraints to some of the columns of your current university affiliations database.
The professors table is almost ready now. However, it still allows for NULLs to be entered. Although some information might be missing about some professors, there’s certainly columns that always need to be specified.
Steps
firstname column.lastname column.Good job – it is no longer possible to add professors which have either their first or last name set to NULL. Likewise, it is no longer possible to update an existing professor and setting their first or last name to NULL.
Execute the following statement:
#> Error: Failed to fetch row : ERROR: null value in column "firstname" of relation "professors" violates not-null constraint
#> DETAIL: Failing row contains (null, Miller, ETH).2.12 Question
Why does this throw an error?
⬜ Professors without first names do not exist.
✅ Because a database constraint is violated.
⬜ Error? This works just fine.
⬜NULLis not put in quotes.
Correct! This statement violates one of the not-null constraints you’ve just specified.
As seen in the video, you add the UNIQUE keyword after the column_name that should be unique. This, of course, only works for new tables:
If you want to add a unique constraint to an existing table, you do it like that:
Note that this is different from the ALTER COLUMN syntax for the not-null constraint. Also, you have to give the constraint a name some_name.
Steps
university_shortname column in universities. Give it the name university_shortname_unq.organization column in organizations. Give it the name organization_unq.Perfect. Making sure universities.university_shortname and organizations.organization only contain unique values is a prerequisite for turning them into so-called primary keys – the subject of the next chapter!
Now let’s get into the best practices of database engineering. It’s time to add primary and foreign keys to the tables. These are two of the most important concepts in databases, and are the building blocks you’ll use to establish relationships between tables.
Theory. Coming soon …
1. Keys and superkeys
Welcome back! Let’s discuss key constraints. They are a very important concept in database systems, so we’ll spend a whole chapter on them.
2. The current database model
Let’s have a look at your current database model first. In the last chapter, you specified attribute constraints, first and foremost data types. You also set not-null and unique constraints on certain attributes. This didn’t actually change the structure of the model, so it still looks the same.
3. The database model with primary keys
By the end of this chapter, the database will look slightly different. You’ll add so-called primary keys to three different tables. You’ll name them “id”. In the entity-relationship diagram, keys are denoted by underlined attribute names. Notice that you’ll add a whole new attribute to the “professors” table, and you’ll modify existing columns of the “organizations” and “universities” tables.
4. What is a key?
Before we go into the nitty-gritty of what a primary key actually is, let’s look at keys in general. Typically a database table has an attribute, or a combination of multiple attributes, whose values are unique across the whole table. Such attributes identify a record uniquely. Normally, a table, as a whole, only contains unique records, meaning that the combination of all attributes is a key in itself. However, it’s not called a key, but a superkey, if attributes from that combination can be removed, and the attributes still uniquely identify records. If all possible attributes have been removed but the records are still uniquely identifiable by the remaining attributes, we speak of a minimal superkey. This is the actual key. So a key is always minimal. Let’s look at an example.
5. An example
Here’s an example that I found in a textbook on database systems. Obviously, the table shows six different cars, so the combination of all attributes is a superkey. If we remove the “year” attribute from the superkey, the six records are still unique, so it’s still a superkey. Actually, there are a lot of possible superkeys in this example.
6. An example (contd.)
However, there are only four minimal superkeys, and these are “license_no”, “serial_no”, and “model”, as well as the combination of “make” and “year”. Remember that superkeys are minimal if no attributes can be removed without losing the uniqueness property. This is trivial for K1 to 3, as they only consist of a single attribute. Also, if we remove “year” from K4, “make” would contain duplicates, and would, therefore, be no longer suited as key. These four minimal superkeys are also called candidate keys. Why candidate keys? In the end, there can only be one key for the table, which has to be chosen from the candidates. More on that in the next video.
7. Let’s discover some keys!
First I want you to have a look at some tables in your database and think about keys.
Your database doesn’t have any defined keys so far, and you don’t know which columns or combinations of columns are suited as keys.
There’s a simple way of finding out whether a certain column (or a combination) contains only unique values – and thus identifies the records in the table.
You already know the SELECT DISTINCT query from the first chapter. Now you just have to wrap everything within the COUNT() function and PostgreSQL will return the number of unique rows for the given columns:
Steps
universities.university_city column.-- Count the number of distinct values in the university_city column
SELECT COUNT(DISTINCT(university_city))
FROM universities;| count |
|---|
| 9 |
Great! So, obviously, the university_city column wouldn\’t lend itself as a key. Why? Because there are only 9 distinct values, but the table has 11 rows.
There’s a very basic way of finding out what qualifies for a key in an existing, populated table:
The table professors has 551 rows. It has only one possible candidate key, which is a combination of two attributes. You might want to try different combinations using the “Run code” button. Once you have found the solution, you can submit your answer.
Steps
| count |
|---|
| 551 |
Indeed, the only combination that uniquely identifies professors is {firstname, lastname}. {firstname, lastname, university_shortname} is a superkey, and all other combinations give duplicate values. Hopefully, the concept of superkeys and keys is now a bit more clear. Let\’s move on to primary keys!
Theory. Coming soon …
1. Primary keys
Okay, now it’s time to look at an actual use case for superkeys, keys, and candidate keys.
2. Primary keys
Primary keys are one of the most important concepts in database design. Almost every database table should have a primary key – chosen by you from the set of candidate keys. The main purpose, as already explained, is uniquely identifying records in a table. This makes it easier to reference these records from other tables, for instance – a concept you will go through in the next and last chapter. You might have already guessed it, but primary keys need to be defined on columns that don’t accept duplicate or null values. Lastly, primary key constraints are time-invariant, meaning that they must hold for the current data in the table – but also for any future data that the table might hold. It is therefore wise to choose columns where values will always be unique and not null.
3. Specifying primary keys
So these two tables accept exactly the same data, however, the latter has an explicit primary key specified. As you can see, specifying primary keys upon table creation is very easy. Primary keys can also be specified like so: This notation is necessary if you want to designate more than one column as the primary key. Beware, that’s still only one primary key, it is just formed by the combination of two columns. Ideally, though, primary keys consist of as few columns as possible!
4. Specifying primary keys (contd.)
Adding primary key constraints to existing tables is the same procedure as adding unique constraints, which you might remember from the last chapter. As with unique constraints, you have to give the constraint a certain name.
5. Your database
In the exercises that follow, you will add primary keys to the tables “universities” and “organizations”. You will add a special type of primary key, a so-called surrogate key, to the table “professors” in the last part of this chapter.
6. Let’s practice!
Let’s go add these keys.
Have a look at the example table from the previous video. As the database designer, you have to make a wise choice as to which column should be the primary key.
license_no | serial_no | make | model | year
--------------------+-----------+------------+---------+------
Texas ABC-739 | A69352 | Ford | Mustang | 2
Florida TVP-347 | B43696 | Oldsmobile | Cutlass | 5
New York MPO-22 | X83554 | Oldsmobile | Delta | 1
California 432-TFY | C43742 | Mercedes | 190-D | 99
California RSK-629 | Y82935 | Toyota | Camry | 4
Texas RSK-629 | U028365 | Jaguar | XJS | 43.6 Question
Which of the following column or column combinations could best serve as primary key?
⬜ PK = {make}
⬜ PK = {model, year}
✅ PK = {license_no}
⬜ PK = {year, make}
Correct! A primary key consisting solely of “license_no” is probably the wisest choice, as license numbers are certainly unique across all registered cars in a country.
Two of the tables in your database already have well-suited candidate keys consisting of one column each: organizations and universities with the organization and university_shortname columns, respectively.
In this exercise, you’ll rename these columns to id using the RENAME COLUMN command and then specify primary key constraints for them. This is as straightforward as adding unique constraints (see the last exercise of Chapter 2):
Note that you can also specify more than one column in the brackets.
Steps
organization column to id in organizations.id a primary key and name it organization_pk.university_shortname column to id in universities.id a primary key and name it university_pk.Good job! That was easy, wasn’t it? Let’s tackle the last table that needs a primary key right now: professors. However, things are going to be different this time, because you’ll add a so-called surrogate key.
Theory. Coming soon …
1. Surrogate keys
Surrogate keys are sort of an artificial primary key. In other words, they are not based on a native column in your data, but on a column that just exists for the sake of having a primary key. Why would you need that?
2. Surrogate keys
There are several reasons for creating an artificial surrogate key. As mentioned before, a primary key is ideally constructed from as few columns as possible. Secondly, the primary key of a record should never change over time. If you define an artificial primary key, ideally consisting of a unique number or string, you can be sure that this number stays the same for each record. Other attributes might change, but the primary key always has the same value for a given record.
3. An example
Let’s look back at the example in the first video of this chapter. I altered it slightly and added the “color” column. In this table, the “license_no” column would be suited as the primary key – the license number is unlikely to change over time, not like the color column, for example, which might change if the car is repainted. So there’s no need for a surrogate key here. However, let’s say there were only these three attributes in the table. The only sensible primary key would be the combination of “make” and “model”, but that’s two columns for the primary key.
4. Adding a surrogate key with serial data type
You could add a new surrogate key column, called “id”, to solve this problem. Actually, there’s a special data type in PostgreSQL that allows the addition of auto-incrementing numbers to an existing table: the “serial” type. It is specified just like any other data type. Once you add a column with the “serial” type, all the records in your table will be numbered. Whenever you add a new record to the table, it will automatically get a number that does not exist yet. There are similar data types in other database management systems, like MySQL.
5. Adding a surrogate key with serial data type (contd.)
Also, if you try to specify an ID that already exists, the primary key constraint will prevent you from doing so. So, after all, the “id” column uniquely identifies each record in this table – which is very useful, for example, when you want to refer to these records from another table. But this will be the subject of the next chapter.
6. Another type of surrogate key
Another strategy for creating a surrogate key is to combine two existing columns into a new one. In this example, we first add a new column with the “varchar” data type. We then “UPDATE” that column with the concatenation of two existing columns. The “CONCAT” function glues together the values of two or more existing columns. Lastly, we turn that new column into a surrogate primary key.
7. Your database
In the exercises, you’ll add a surrogate key to the “professors” table, because the existing attributes are not really suited as primary key. Theoretically, there could be more than one professor with the same name working for one university, resulting in duplicates. With an auto-incrementing “id” column as the primary key, you make sure that each professor can be uniquely referred to. This was not necessary for organizations and universities, as their names can be assumed to be unique across these tables. In other words: It is unlikely that two organizations with the same name exist, solely for trademark reasons. The same goes for universities.
8. Let’s try this!
Let’s try this out before you move on to the last chapter.
Since there’s no single column candidate key in professors (only a composite key candidate consisting of firstname, lastname), you’ll add a new column id to that table.
This column has a special data type serial, which turns the column into an auto-incrementing number. This means that, whenever you add a new professor to the table, it will automatically get an id that does not exist yet in the table: a perfect primary key!
Steps
id with data type serial to the professors table.id a primary key and name it professors_pkey.professors.| firstname | lastname | university_shortname | id |
|---|---|---|---|
| Michel | Rappaz | EPF | 1 |
| Hilal | Lashuel | EPF | 2 |
| Jeffrey | Huang | EPF | 3 |
| Pierre | Magistretti | EPF | 4 |
| Paolo | Ienne | EPF | 5 |
| Frédéric | Kaplan | EPF | 6 |
| Olivier | Hari | UNE | 7 |
| Christian | Hesse | UBE | 8 |
| Majed | Chergui | EPF | 9 |
| Douglas | Hanahan | EPF | 10 |
Well done. As you can see, PostgreSQL has automatically numbered the rows with the id column, which now functions as a (surrogate) primary key – it uniquely identifies professors.
Another strategy to add a surrogate key to an existing table is to concatenate existing columns with the CONCAT() function.
Let’s think of the following example table:
The table is populated with 10 rows of completely fictional data.
Unfortunately, the table doesn’t have a primary key yet. None of the columns consists of only unique values, so some columns can be combined to form a key.
In the course of the following exercises, you will combine make and model into such a surrogate key.
Steps
make and model columns.-- Count the number of distinct rows with columns make, model
SELECT COUNT(DISTINCT(make, model))
FROM cars;| count |
|---|
| 10 |
id with the data type varchar(128).-- Count the number of distinct rows with columns make, model
SELECT COUNT(DISTINCT(make, model))
FROM cars;| count |
|---|
| 10 |
make and model into id using an UPDATE table_name SET column_name = ... query and the CONCAT() function.id a primary key and name it id_pk.| make | model | mpg | id |
|---|---|---|---|
| Subaru | Forester | 24 | SubaruForester |
| Opel | Astra | 45 | OpelAstra |
| Opel | Vectra | 40 | OpelVectra |
| Ford | Avenger | 30 | FordAvenger |
| Ford | Galaxy | 30 | FordGalaxy |
| Toyota | Prius | 50 | ToyotaPrius |
| Toyota | Speedster | 30 | ToyotaSpeedster |
| Toyota | Galaxy | 20 | ToyotaGalaxy |
| Mitsubishi | Forester | 10 | MitsubishiForester |
| Mitsubishi | Galaxy | 30 | MitsubishiGalaxy |
Good job! These were quite some steps, but you’ve managed! Let’s look into another method of adding a surrogate key now.
Before you move on to the next chapter, let’s quickly review what you’ve learned so far about attributes and key constraints. If you’re unsure about the answer, please quickly review chapters 2 and 3, respectively.
Let’s think of an entity type “student”. A student has:
students with the correct column types.PRIMARY KEY for the social security number ssn.Note that there is no formal length requirement for the integer column. The application would have to make sure it’s a correct SSN!
Great! Looks like you are ready for the last chapter of this course, where you\’ll connect tables in your database.
In the final chapter, you’ll leverage foreign keys to connect tables and establish relationships that will greatly benefit your data quality. And you’ll run ad hoc analyses on your new database.
Theory. Coming soon …
1. Model 1:N relationships with foreign keys
Welcome to the last chapter of this course. Now it’s time to make use of key constraints.
2. The current database model
Here’s your current database model. The three entity types “professors”, “organizations”, and “universities” all have primary keys – but “affiliations” doesn’t, for a specific reason that will be revealed in this chapter.
3. The next database model
Next up, you’ll model a so-called relationship type between “professors” and “universities”. As you know, in your database, each professor works for a university. In the ER diagram, this is drawn with a rhombus. The small numbers specify the cardinality of the relationship: a professor works for at most one university, while a university can have any number of professors working for it – even zero.
4. Implementing relationships with foreign keys
Such relationships are implemented with foreign keys. Foreign keys are designated columns that point to a primary key of another table. There are some restrictions for foreign keys. First, the domain and the data type must be the same as one of the primary key. Secondly, only foreign key values are allowed that exist as values in the primary key of the referenced table. This is the actual foreign key constraint, also called “referential integrity”. You’ll dig into referential integrity at the end of this chapter. Lastly, a foreign key is not necessarily an actual key, because duplicates and “NULL” values are allowed. Let’s have a look at your database.
5. A query
As you can see, the column “university_shortname” of “professors” has the same domain as the “id” column of the “universities” table. If you go through each record of “professors”, you can always find the respective “id” in the “universities” table. So both criteria for a foreign key in the table “professors” referencing “universities” are fulfilled. Also, you see that “university_shortname” is not really a key because there are duplicates. For example, the id “EPF” and “UBE” occur three times each.
6. Specifying foreign keys
When you create a new table, you can specify a foreign key similarly to a primary key. Let’s look at two example tables. First, we create a “manufacturers” table with a primary key called “name”. Then we create a table “cars”, that also has a primary key, called “model”. As each car is produced by a certain manufacturer, it makes sense to also add a foreign key to this table. We do that by writing the “REFERENCES” keyword, followed by the referenced table and its primary key in brackets. From now on, only cars with valid and existing manufacturers may be entered into that table. Trying to enter models with manufacturers that are not yet stored in the “manufacturers” table won’t be possible, thanks to the foreign key constraint.
7. Specifying foreign keys to existing tables
Again, the syntax for adding foreign keys to existing tables is the same as the one for adding primary keys and unique constraints.
8. Let’s implement this!
Okay, let’s have a look at your database and implement a simple relationship between “professors” and “universities”.
In your database, you want the professors table to reference the universities table. You can do that by specifying a column in professors table that references a column in the universities table.
As just shown in the video, the syntax for that looks like this:
Table a should now refer to table b, via b_id, which points to id. a_fkey is, as usual, a constraint name you can choose on your own.
Pay attention to the naming convention employed here: Usually, a foreign key referencing another primary key with name id is named x_id, where x is the name of the referencing table in the singular form.
Steps
university_shortname column to university_id in professors.university_id column in professors that references the id column in universities.professors_fkey.Perfect! Now, the professors table has a link to the universities table. Each professor belongs to exactly one university.
Foreign key constraints help you to keep order in your database mini-world. In your database, for instance, only professors belonging to Swiss universities should be allowed, as only Swiss universities are part of the universities table.
The foreign key on professors referencing universities you just created thus makes sure that only existing universities can be specified when inserting new data. Let’s test this!
Steps
university_id so that it actually reflects where Albert Einstein wrote his dissertation and became a professor – at the University of Zurich (UZH)!-- Try to insert a new professor
INSERT INTO professors (firstname, lastname, university_id)
VALUES ('Albert', 'Einstein', 'MIT');#> Error: Failed to fetch row : ERROR: insert or update on table "professors" violates foreign key constraint "professors_fkey"
#> DETAIL: Key (university_id)=(MIT) is not present in table "universities".Great! As you can see, inserting a professor with non-existing university IDs violates the foreign key constraint you\’ve just added. This also makes sure that all universities are spelled equally – adding to data consistency.
Let’s join these two tables to analyze the data further!
You might already know how SQL joins work from the Intro to SQL for Data Science course (last exercise) or from Joining Data in PostgreSQL.
Here’s a quick recap on how joins generally work:
While foreign keys and primary keys are not strictly necessary for join queries, they greatly help by telling you what to expect. For instance, you can be sure that records referenced from table A will always be present in table B – so a join from table A will always find something in table B. If not, the foreign key constraint would be violated.
Steps
JOIN professors with universities on professors.university_id = universities.id, i.e., retain all records where the foreign key of professors is equal to the primary key of universities.university_city = 'Zurich'.-- Select all professors working for universities in the city of Zurich
SELECT professors.lastname, universities.id, universities.university_city
FROM professors
JOIN universities
ON professors.university_id = universities.id
WHERE universities.university_city = 'Zurich';| lastname | id | university_city |
|---|---|---|
| Grote | ETH | Zurich |
| Carreira | ETH | Zurich |
| Wennemers | ETH | Zurich |
| Hafen | ETH | Zurich |
| Saar | ETH | Zurich |
| Loeliger | ETH | Zurich |
| Schönsleben | ETH | Zurich |
| Bühler | UZH | Zurich |
| Hellweg | ETH | Zurich |
| Gugerli | UZH | Zurich |
That’s a long query! First, the university belonging to each professor was attached with the JOIN operation. Then, only professors having \“Zurich\”” as university city were retained with the WHERE clause.
Theory. Coming soon …
1. Model more complex relationships
In the last few exercises, you made your first steps in modeling and implementing 1:N-relationships. Now it’s time to look at more complex relationships between tables.
2. The current database model
So you’ve added a 1:N-relationship between professors and universities. Such relationships have to be implemented with one foreign key in the table that has at most one foreign entity associated. In this case, that’s the “professors” table, as professors cannot have more than one university associated. Now, what about affiliations? We know that a professor can have more than one affiliation with organizations, for instance, as a chairman of a bank and as a president of a golf club. On the other hand, organizations can also have more than one professor connected to them. Let’s look at the entity-relationship diagram that models this.
3. The final database model
There are a couple of things that are new. First of all, a new relationship between organizations and professors was added. This is an N:M relationship, not an 1:N relationship as with professors and universities. This depicts the fact that a professor can be affiliated with more than one organization and vice versa. Also, it has an own attribute, the function. Remember that each affiliation comes with a function, for instance, “chairman”. The second thing you’ll notice is that the affiliations entity type disappeared altogether. For clarity, I still included it in the diagram, but it’s no longer needed. However, you’ll still have four tables: Three for the entities “professors”, “universities” and “organizations”, and one for the N:M-relationship between “professors” and “organizations”.
4. How to implement N:M-relationships
Such a relationship is implemented with an ordinary database table that contains two foreign keys that point to both connected entities. In this case, that’s a foreign key pointing to the “professors.id” column, and one pointing to the “organizations.id” column. Also, additional attributes, in this case “function”, need to be included. If you were to create that relationship table from scratch, you would define it as shown. Note that “professor_id” is stored as “integer”, as the primary key it refers to has the type “serial”, which is also an integer. On the other hand, “organization_id” has “varchar(256)” as type, conforming to the primary key in the “organizations” table. One last thing: Notice that no primary key is defined here because a professor can theoretically have multiple functions in one organization. One could define the combination of all three attributes as the primary key in order to have some form of unique constraint in that table, but that would be a bit over the top.
5. Time to implement this!
Since you already have a pre-populated affiliations table, things are not going to be so straightforward. You’ll need to link and migrate the data to a new table to implement this relationship. This will be the goal of the following exercises.
At the moment, the affiliations table has the structure {firstname, lastname, function, organization}, as you can see in the preview at the bottom right. In the next three exercises, you’re going to turn this table into the form {professor_id, organization_id, function}, with professor_id and organization_id being foreign keys that point to the respective tables.
You’re going to transform the affiliations table in-place, i.e., without creating a temporary table to cache your intermediate results.
Steps
professor_id column with integer data type to affiliations, and declare it to be a foreign key that references the id column in professors.organization column in affiliations to organization_id.organization_id so that it references the id column in organizations.Perfect! Making organization_id a foreign key worked flawlessly because these organizations actually exist in the organizations table. That was only the first part, though. Now it\’s time to update professor_id in affiliations – so that it correctly refers to the corresponding professors.
Now it’s time to also populate professors_id. You’ll take the ID directly from professors.
Here’s a way to update columns of a table based on values in another table:
This query does the following:
The conditions usually compare other columns of both tables, e.g. table_a.some_column = table_b.some_column. Of course, this query only makes sense if there is only one matching row in table_b.
Steps
affiliations by fetching 10 rows and all columns.| firstname | lastname | function | organization_id | professor_id |
|---|---|---|---|---|
| Dimos | Poulikakos | VR-Mandat | Scrona AG | NA |
| Francesco | Stellacci | Co-editor in Chief, Nanoscale | Royal Chemistry Society, UK | NA |
| Alexander | Fust | Fachexperte und Coach für Designer Startups | Creative Hub | NA |
| Jürgen | Brugger | Proposal reviewing HEPIA | HES Campus Biotech, Genève | NA |
| Hervé | Bourlard | Director | Idiap Research Institute | NA |
| Ioannis | Papadopoulos | Mandat | Schweizerischer Nationalfonds (SNF) | NA |
| Olaf | Blanke | Professeur à 20% | Université de Genève | NA |
| Leo | Staub | Präsident Verwaltungsrat | Genossenschaft Migros Ostschweiz | NA |
| Pascal | Pichonnaz | Vize-Präsident | EKK (Eidgenössische Konsumenten Kommission) | NA |
| Dietmar | Grichnik | Präsident | Swiss Startup Monitor Stiftung | NA |
professor_id column with the corresponding value of the id column in professors.“Corresponding” means rows in professors where the firstname and lastname are identical to the ones in affiliations.
affiliations again. Have the professor_ids been correctly matched?| firstname | lastname | function | organization_id | professor_id |
|---|---|---|---|---|
| Françoise Gisou van der | Goot Grunberg | Conseil de fondation et Conseil Scientifique de la Fondation Jeantet | Fondation Jeantet, Genève | NA |
| Walter Hans Jakob | Kaufmann | VR-Mandat | dsp Ingenieure & Planer AG | NA |
| Jérôme Jean-Constant | Faist | VR-Mandat | Alpes Lasers S.A. | NA |
| Johan Olof Anders | Robertsson | Geschäftsführer | Robertsson Industrial Geoscience Innovation GmbH | NA |
| Françoise Gisou van der | Goot Grunberg | EMBO YIP (Young Investigator Program) committee | EMBO, Heidelberg | NA |
| Alain | Wegmann | Conseil informatique | TAG Aviation, Genève | 462 |
| Françoise Gisou van der | Goot Grunberg | Conseil Suisse de la Science et de l’Innovation | CSSI Bern | NA |
| Françoise Gisou van der | Goot Grunberg | Diverses commissions du SNF | SNF Bern | NA |
| Françoise Gisou van der | Goot Grunberg | Scientific Advisory Board Clinical Research Department | Univ Bern | NA |
| Jérôme Jean-Constant | Faist | NA | Centre Suisse d’Electronique et de Microtechnique (CSEM) | NA |
Wow, that was a thing! As you can see, the correct professors.id has been inserted into professor_id for each record, thanks to the matching firstname and lastname in both tables.
The firstname and lastname columns of affiliations were used to establish a link to the professors table in the last exercise – so the appropriate professor IDs could be copied over. This only worked because there is exactly one corresponding professor for each row in affiliations. In other words: {firstname, lastname} is a candidate key of professors – a unique combination of columns.
It isn’t one in affiliations though, because, as said in the video, professors can have more than one affiliation.
Because professors are referenced by professor_id now, the firstname and lastname columns are no longer needed, so it’s time to drop them. After all, one of the goals of a database is to reduce redundancy where possible.
Steps
firstname and lastname columns from the affiliations table.Good job! Now the affiliations table that models the N:M-relationship between professors and organizations is finally complete.
Theory. Coming soon …
1. Referential integrity
We’ll now talk about one of the most important concepts in database systems: referential integrity. It’s a very simple concept…
2. Referential integrity
…that states that a record referencing another record in another table must always refer to an existing record. In other words: A record in table A cannot point to a record in table B that does not exist. Referential integrity is a constraint that always concerns two tables, and is enforced through foreign keys, as you’ve seen in the previous lessons of this chapter. So if you define a foreign key in the table “professors” referencing the table “universities”, referential integrity is held from “professors” to “universities”.
3. Referential integrity violations
Referential integrity can be violated in two ways. Let’s say table A references table B. So if a record in table B that is already referenced from table A is deleted, you have a violation. On the other hand, if you try to insert a record in table A that refers to something that does not exist in table B, you also violate the principle. And that’s the main reason for foreign keys – they will throw errors and stop you from accidentally doing these things.
4. Dealing with violations
However, throwing an error is not the only option. If you specify a foreign key on a column, you can actually tell the database system what should happen if an entry in the referenced table is deleted. By default, the “ON DELETE NO ACTION” keyword is automatically appended to a foreign key definition, like in the example here. This means that if you try to delete a record in table B which is referenced from table A, the system will throw an error. However, there are other options. For example, there’s the “CASCADE” option, which will first allow the deletion of the record in table B, and then will automatically delete all referencing records in table A. So that deletion is cascaded.
5. Dealing with violations, contd.
There are even more options. The “RESTRICT” option is almost identical to the “NO ACTION” option. The differences are technical and beyond the scope of this course. More interesting is the “SET NULL” option. It will set the value of the foreign key for this record to “NULL”. The “SET DEFAULT” option only works if you have specified a default value for a column. It automatically changes the referencing column to a certain default value if the referenced record is deleted. Setting default values is also beyond the scope of this course, but this option is still good to know.
6. Let’s look at some examples!
Let’s practice this a bit and change the referential integrity behavior of your database.
#> Error: Failed to fetch row : ERROR: update or delete on table "universities" violates foreign key constraint "professors_fkey" on table "professors"
#> DETAIL: Key (id)=(EPF) is still referenced from table "professors".4.11 Question
Given the current state of your database, what happens if you execute the following SQL statement?
⬜ It throws an error because the university with ID “EPF” does not exist.
⬜ The university with ID “EPF” is deleted.
⬜ It fails because referential integrity fromuniversitiestoprofessorsis violated.
✅ It fails because referential integrity fromprofessorstouniversitiesis violated.
Correct! You defined a foreign key on professors.university_id that references universities.id, so referential integrity is said to hold from professors to universities.
So far, you implemented three foreign key constraints:
professors.university_id to universities.idaffiliations.organization_id to organizations.idaffiliations.professor_id to professors.idThese foreign keys currently have the behavior ON DELETE NO ACTION. Here, you’re going to change that behavior for the column referencing organizations from affiliations. If an organization is deleted, all its affiliations (by any professor) should also be deleted.
Altering a key constraint doesn’t work with ALTER COLUMN. Instead, you have to DROP the key constraint and then ADD a new one with a different ON DELETE behavior.
For deleting constraints, though, you need to know their name. This information is also stored in information_schema.
Steps
table_constraints in information_schema.-- Identify the correct constraint name
SELECT constraint_name, table_name, constraint_type
FROM information_schema.table_constraints
WHERE constraint_type = 'FOREIGN KEY';| constraint_name | table_name | constraint_type |
|---|---|---|
| professors_fkey | professors | FOREIGN KEY |
| affiliations_professor_id_fkey | affiliations | FOREIGN KEY |
| affiliations_organization_fkey | affiliations | FOREIGN KEY |
affiliations_organization_fkey foreign key constraint in affiliations.affiliations that CASCADEs deletion if a referenced record is deleted from organizations. Name it affiliations_organization_id_fkey.DELETE and SELECT queries to double check that the deletion cascade actually works.-- Check that no more affiliations with this organization exist
SELECT * FROM affiliations
WHERE organization_id = 'CUREM';| function | organization_id | professor_id |
|---|
Good job. As you can see, whenever an organization referenced by an affiliation is deleted, the affiliations also gets deleted. It is your job as database designer to judge whether this is a sensible configuration. Sometimes, setting values to NULL or to restrict deletion altogether might make more sense!
Theory. Coming soon …
1. Roundup
Congratulations, you’re almost done. Let’s quickly revise what you’ve done throughout this course.
2. How you’ve transformed the database
You started with a simple table with a lot of redundancy. You might be used to such tables when working with flat files like CSVs or Excel files. Throughout the course, you transformed it step by step into the database schema on the right – only by executing SQL queries. You’ve defined column data types, added primary keys and foreign keys, and through that, specified relationships between tables. All these measures will guarantee better data consistency and therefore quality. This is especially helpful if you add new data to the database but also makes analyzing the data easier.
3. The database ecosystem
To go further from here, it’s useful to look at the bigger picture for a minute. In this course, you’ve transformed a database. You did that with PostgreSQL, which is also called a “Database Management System”, or DBMS. The DBMS and one or more databases together form the “Database System”. The DBMS exposes a query interface where you can run ad-hoc analyses and queries with SQL. However, you can also access this interface through other client applications. You could, for example, program a Python script that connects to the database, loads data from it, and visualizes it.
4. The database ecosystem
In the remainder of this course, you’ll no longer manipulate data in your database system, but employ some analysis queries on your database. This will be a quick repetition of what you’ve learned in previous SQL courses such as “Intro to SQL for Data Science”, but it will also demonstrate the advantages of having a database instead of a flat file in the first place.
5. Thank you!
For me it’s time to say goodbye, thank you for taking this course, and I hope you will soon build your first relational database with the knowledge you’ve gained here.
Now that your data is ready for analysis, let’s run some exemplary SQL queries on the database. You’ll now use already known concepts such as grouping by columns and joining tables.
In this exercise, you will find out which university has the most affiliations (through its professors). For that, you need both affiliations and professors tables, as the latter also holds the university_id.
As a quick repetition, remember that joins have the following structure:
This results in a combination of table_a and table_b, but only with rows where table_a.column is equal to table_b.column.
Steps
-- Count the total number of affiliations per university
SELECT COUNT(*), professors.university_id
FROM affiliations
JOIN professors
ON affiliations.professor_id = professors.id
-- Group by the university ids of professors
GROUP BY professors.university_id
ORDER BY count DESC;| count | university_id |
|---|---|
| 572 | EPF |
| 272 | USG |
| 162 | UBE |
| 128 | ETH |
| 75 | UBA |
| 40 | UFR |
| 36 | UNE |
| 35 | ULA |
| 33 | UGE |
| 7 | UZH |
Very good. As you can see, the count of affiliations is completely different from university to university.
In this last exercise, your task is to find the university city of the professor with the most affiliations in the sector “Media & communication”.
For this,
Steps
affiliations, professors, organizations, and universities) and look at the result.-- Join all tables
SELECT *
FROM affiliations
JOIN professors
ON affiliations.professor_id = professors.id
JOIN organizations
ON affiliations.organization_id = organizations.id
JOIN universities
ON professors.university_id = universities.id;| function | organization_id | professor_id | firstname | lastname | university_id | id | id..8 | organization_sector | id..10 | university | university_city |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Conseil informatique | TAG Aviation, Genève | 462 | Alain | Wegmann | EPF | 462 | TAG Aviation, Genève | Energy, environment & mobility | EPF | ETH Lausanne | Lausanne |
| NA | WHO, Geneva | 534 | Matthias | Egger | UBE | 534 | WHO, Geneva | Pharma & health | UBE | Uni Bern | Bern |
| NA | Securitas AG | 242 | Artur | Baldauf | UBE | 242 | Securitas AG | Politics, administration, justice system & security sector | UBE | Uni Bern | Bern |
| NA | Foundation of Talents | 407 | Achim | Conzelmann | UBE | 407 | Foundation of Talents | Society, Social, Culture & Sports | UBE | Uni Bern | Bern |
| NA | PH Bern, Schulrat | 407 | Achim | Conzelmann | UBE | 407 | PH Bern, Schulrat | Education & research | UBE | Uni Bern | Bern |
| NA | Büro Vatter AG | 386 | Adrian | Vatter | UBE | 386 | Büro Vatter AG | Consulting, public relations, legal & trust | UBE | Uni Bern | Bern |
| NA | Curt Rommel Stiftung | 344 | Adriano | Marantelli | UBE | 344 | Curt Rommel Stiftung | Education & research | UBE | Uni Bern | Bern |
| NA | Vereinsvorstand BEWEST (Weiterbildungsverein) | 344 | Adriano | Marantelli | UBE | 344 | Vereinsvorstand BEWEST (Weiterbildungsverein) | Education & research | UBE | Uni Bern | Bern |
| NA | Stiftung Archiv für schweizerisches Abgaberecht | 344 | Adriano | Marantelli | UBE | 344 | Stiftung Archiv für schweizerisches Abgaberecht | Society, Social, Culture & Sports | UBE | Uni Bern | Bern |
| Conseil informatique (non-payé) | Aeroport Genève | 462 | Alain | Wegmann | EPF | 462 | Aeroport Genève | Energy, environment & mobility | EPF | ETH Lausanne | Lausanne |
-- Group the table by organization sector, professor ID and university city
SELECT COUNT(*), organizations.organization_sector,
professors.id, universities.university_city
FROM affiliations
JOIN professors
ON affiliations.professor_id = professors.id
JOIN organizations
ON affiliations.organization_id = organizations.id
JOIN universities
ON professors.university_id = universities.id
GROUP BY organizations.organization_sector,
professors.id, universities.university_city;| count | organization_sector | id | university_city |
|---|---|---|---|
| 1 | Technology | 135 | Zurich |
| 5 | Education & research | 113 | Basel |
| 1 | Technology | 363 | Lausanne |
| 1 | Industry, construction & agriculture | 39 | Zurich |
| 2 | Society, Social, Culture & Sports | 182 | Zurich |
| 1 | Pharma & health | 377 | Bern |
| 1 | Media & communication | 50 | Lausanne |
| 4 | Energy, environment & mobility | 320 | Saint Gallen |
| 1 | Education & research | 327 | Fribourg |
| 1 | Energy, environment & mobility | 194 | Lausanne |
-- Filter the table and sort it
SELECT COUNT(*), organizations.organization_sector,
professors.id, universities.university_city
FROM affiliations
JOIN professors
ON affiliations.professor_id = professors.id
JOIN organizations
ON affiliations.organization_id = organizations.id
JOIN universities
ON professors.university_id = universities.id
WHERE organizations.organization_sector = 'Media & communication'
GROUP BY organizations.organization_sector,
professors.id, universities.university_city
ORDER BY count DESC;| count | organization_sector | id | university_city |
|---|---|---|---|
| 4 | Media & communication | 345 | Lausanne |
| 3 | Media & communication | 253 | Saint Gallen |
| 3 | Media & communication | 322 | Lausanne |
| 2 | Media & communication | 453 | Saint Gallen |
| 2 | Media & communication | 380 | Saint Gallen |
| 2 | Media & communication | 290 | Saint Gallen |
| 2 | Media & communication | 439 | Lausanne |
| 2 | Media & communication | 378 | Lausanne |
| 2 | Media & communication | 452 | Zurich |
| 1 | Media & communication | 115 | Lausanne |
Good job! The professor with id 538 has the most affiliations in the “Media & communication” sector, and he or she lives in the city of Lausanne. Thanks to your database design, you can be sure that the data you’ve just queried is consistent. Of course, you could also put university_city and organization_sector in their own tables, making the data model even more formal. However, in database design, you have to strike a balance between modeling overhead, desired data consistency, and usability for queries like the one you\’ve just wrote. Congratulations, you made it to the end!