CoreSignal Analysis
Current Status
Hamburg University of Technology
Monday, 17th of February 2025
Table of Contents
Preperation
Input for CoreSignal
Data sources I
1st objective: Prepare CrunchBase / PitchBook and CoreSignal data
Load & Init Companies (CrunchBase, PitchBook & CoreSignal)
Crunchbase data contains 150,838 startups with a valid funding trajectory.
- Must have identifier (domain, linkedin)
- Clean identifiers
- Remove duplicates
library(stringr)
fc_unnested_tbl |>
# 1. At least 1 identifier: 4.518 observations are filtered out
filter(if_any(c(domain, linkedin_url), ~!is.na(.))) |>
# 2. Extract linkedin handle & clean domains
mutate(linkedin_handle = linkedin_url |> str_extract("(?<=linkedin\\.com/company/).*?(?=(?:\\?|$|/))")) |>
mutate(domain = domain |> clean_domain()) |>
# 3. Remove 532 duplicates
distinct()–> 145.991 distinct examineable companies.
Issue: Some extracted domains are not unique and associated with multiple companies.
Manual Cleaning: Domains with a count exceeding two were analyzed and set to NA if they do not correspond to the actual one.
# ANALYZE
# fc_wrangled_tbl |>
# distinct(company_id, domain) |>
# count(domain, sort = T) |>
# filter(n>2)`
unwanted_domains_cb <- c("webflow.io", "angel.co", "weebly.com", "wordpress.com", "wixsite.com", "squarespace.com",
"webflow.io", "crypt2esports.com", "myshopify.com", "business.site", "mystrikingly.com",
"launchrock.com", "square.site", "google.com", "sites.google.com", "t.co", "linktr.ee",
"netlify.app", "itunes.apple.com", "apple.com", "crunchb.com", "tumblr.com", "linkedin.com",
"godaddysites.com", "mit.edu", "paloaltonetworks.com", " wpengine.com", "facebook.com",
"intuit.com", "medium.com", "salesforce.com", "strikingly.com", "wix.com", "cisco.com",
"digi.me", "apps.apple.com", "bit.ly", "fleek.co", "harvard.edu", "ibm.com", "jimdo.com",
"myftpupload.com", "odoo.com", "storenvy.com", "twitter.com", "umd.edu", "umich.edu", "vmware.com", "webs.com")
# Not all observations with unwanted domains are bad per se:
wanted_ids_cb <- c(angel = 128006, `catapult-centres-uk` = 115854, digime1 = 140904, digimi2 = 95430, fleek = 50738,
jimdo = 108655, medium = 113415, storenvy = 85742, strikingly = 95831, substack = 34304,
tumblr = 84838, twitter = 53139, weebly = 91365, wpengine = 91720)
# Set misleading domains to NA
funded_companies_clnd <- fc_wrangled_tbl |>
mutate(domain = if_else(
domain %in% unwanted_domains_cb & !(company_id %in% wanted_ids_cb),
NA_character_, domain))It appears that CoreSignal has been able to locate 45.026 companies within our gathered data.
Nothing to wrangle …
Important
More cleaning necessary (same as CBPB)! The task was undertaken with a limited degree of enthusiasm.
unwanted_domains_cs <- c("bit.ly", "linktr.ee", "facebook.com", "linkedin.com", "twitter.com", "crunchbase.com")
wanted_ids_cs <- c(crunchbase = 1634413, linkedin = 8568581, twitter = 24745469)
cs_companies_base_clnd <- cs_companies_base_wrangled |>
mutate(domain_cs = if_else(
domain_cs %in% unwanted_domains_cs & !(id_cs %in% wanted_ids_cs),
NA_character_,
domain_cs)
)Data sources II
2nd objective: Match CrunchBase / PitchBook with CoreSignal data
Join companies, member experiences and funding information
We were able to match 37.287 CS & CB/PB companies.
cb_cs_joined <- funded_companies_clnd |>
# Leftjoins
left_join(cs_companies_base_clnd |> select(id_cs, domain_cs), by = c(domain = "domain_cs"), na_matches = "never") |>
left_join(cs_companies_base_clnd |> select(id_cs, linkedin_handle_cs), by = c(linkedin_handle = "linkedin_handle_cs"), na_matches = "never") |>
# Remove obs with no cs_id
filter(!is.na(id_cs)) |>
# Remove matches, that matched different domains, but same company (e.g. company_id: 83060, id_cs: 4507928) block.xyz & squareup.com
select(company_id, id_cs) |>
distinct()
cb_cs_joinedWe got over 460 million employment observations from CoreSignal.
But only ~50 Mil distinct employments
#> FileSystemDataset with 1 Parquet file
#> 51,621,196 rows x 10 columns
#> $ id_tie <int32> 16615559, 16615560, 16615561, 16615562, 1661556…
#> $ id <double> 2244288231, 254049663, 948937291, 254049667, 25…
#> $ member_id <int32> 179313066, 179313066, 179313066, 179313066, 179…
#> $ company_id <int32> 865089, 9098713, 9098713, NA, 865089, 9020540, …
#> $ company_name <string> "heritage community bank", "aurora bank fsb", "…
#> $ title <string> "AVP Chief Compliance/BSA Officer", "AVP Compli…
#> $ date_from_parsed <date32[day]> 2010-02-01, 2012-07-01, 2011-11-01, 1997-07-01,…
#> $ date_to_parsed <date32[day]> 2011-11-01, 2013-06-01, 2012-07-01, 2006-05-01,…
#> $ date_from_parsed_year <int32> 2010, 2012, 2011, 1997, 2006, 2019, 2017, 2021,…
#> $ date_to_parsed_year <int32> 2011, 2013, 2012, 2006, 2010, 2021, 2018, NA, 1…
#> Call `print()` for full schema detailsExample
me_orig <- open_dataset("~/02_diss/01_coresignal/02_data/member_experience/me_orig/")
me_dist <- open_dataset("~/02_diss/01_coresignal/02_data/member_experience/me_dist/")
me_orig |> filter(member_id == 4257, company_id == 9007053) |> collect() |> as_tibble() |> arrange(date_from_parsed) |> print(n=19)
me_dist |> filter(member_id == 4257, company_id == 9007053) |> collect() |> as_tibble() |> arrange(date_from_parsed)Over 10 million (valid: must have starting date) employments at our crunchbase / pitchbook data set companies. 385.100 with a title containing the string founder.
# Distinct company ids
cb_cs_joined_cs_ids <- cb_cs_joined |> distinct(id_cs) |> pull(id_cs)
me_wrangled_prqt <- me_dist8_prqt |>
# Select features
select(member_id, company_id, exp_id = "id", date_from_parsed) |>
# Select observations
filter(company_id %in% cb_cs_joined_cs_ids) |>
# - 967.080 observations (date_to not considered yet)
filter(!is.na(date_from_parsed)) |>
# Add suffix to col names
rename_with(~ paste(., "cs", sep = "_")) |>
compute()
me_wrangled_prqt |>
glimpse()#> Table
#> 11,050,164 rows x 4 columns
#> $ member_id_cs <int32> 9436436, 9436453, 9436478, 9436478, 9436513,…
#> $ company_id_cs <int32> 573738, 3073966, 4577566, 4577566, 4577566, …
#> $ exp_id_cs <double> 1891262301, 923902432, 1399967039, 525842890…
#> $ date_from_parsed_cs <date32[day]> 2018-04-01, 2015-04-01, 2006-01-01, 2004-03-…
#> Call `print()` for full schema detailsMultiple Funding Dates –> Take oldest
Example of funding round data:
#> Rows: 15
#> Columns: 14
#> $ round_id <int> 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, …
#> $ round_uuid_pb <chr> NA, "47208-70T", NA, "58843-18T", NA, NA, NA, "78…
#> $ round_uuid_cb <chr> "a6d3bfd9-5afa-47ce-86de-30a3abad6c9b", NA, "ea3b…
#> $ announced_on <date> 2013-01-01, 2014-04-01, 2015-06-01, 2015-10-07, …
#> $ round_new <int> 1, 2, 3, 4, 5, 6, 7, 8, 8, 9, 10, 11, 12, 12, 13
#> $ round <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15
#> $ exit_cycle <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1
#> $ last <int> 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 1…
#> $ round_type_new <fct> Seed, Series A, Series B, Series C, Series D, Ser…
#> $ round_type <list> "angel", "angel", "early_vc", "early_vc", "conver…
#> $ round_types <list> <"angel", "angel_group", "investor", "company", "…
#> $ raised_amount <dbl> NA, 520000, NA, 1399999, NA, NA, NA, 3250000, NA,…
#> $ post_money_valuation <dbl> NA, NA, NA, 3399998, NA, NA, NA, 10249998, NA, N…
#> $ investors_in_round <list> [<tbl_df[1 x 11]>], [<tbl_df[1 x 11]>], [<tbl_df…- Joining via
dplyrdue to memory constraint not possible. - Joining via
Arrowdue to structure constraints not possible. - –> Joining via
data.tablemost efficient.
Conversion to data.tables necessary:
# 1. Funding Data
# 1.1 Level 1
fc_wrangled_dt |> setDT()
# 1.2 Funding Data Level 2 (funding_rounds)
purrr::walk(fc_wrangled_dt$funding_rounds, setDT)
# 1.3 Remove unnecessary columns + initialize dummy for before_join
purrr::walk(fc_wrangled_dt$funding_rounds, ~ .x[,
`:=`(round_uuid_pb = NULL, round_uuid_cb = NULL, round_new = NULL, round = NULL,
exit_cycle = NULL, last = NULL, round_type = NULL, round_type_new = NULL,
round_types = NULL, post_money_valuation = NULL, investors_in_round = NULL, before_join = NA)
]
)
# 2. Matching Table
cb_cs_joined_slct_dt |> setDT()
# 3. Member experiences
me_wrangled_dt <- me_wrangled_prqt |> collect()Working data.table solution (efficiency increase through join by reference possible).
# 1. Add company_id from funded_companies to member experiences
me_joined_dt <- cb_cs_joined_slct_dt[me_wrangled_dt, on = .(id_cs = company_id_cs), allow.cartesian = TRUE]
#> 12.978.226
# 2. Add funding data from funded_companies
me_joined_dt <- fc_wrangled_dt[me_joined_dt, on = .(company_id)]
#> 12.270.572
# 3. Remove duplicates (why are there any?)
me_joined_dt <- unique(me_joined_dt, by = setdiff(names(me_joined_dt), "funding_rounds"))
#> 12.270.572 .... No duplicates anymore. Removed from cb_cs_joined_slct_dtNot working dplyr solution
Arrow because of nested funding data not possible.
Analysis
Using domain knowledge to extract features
Feature Engineering
How many month have passed since the company was founded and before the person joined the company (in months)?
Unnesting necessary due to memory constraints (takes multiple hours … to be measured).
Add feature whether or not member joined before Announcement of a funding round:
#> FileSystemDataset with 1 Parquet file
#> 88,429,236 rows x 15 columns
#> $ company_id_cbpb <int32> 85514, 85514, 85514, 85514, 85514, 85514, 85…
#> $ founded_on_cbpb <date32[day]> 2007-01-01, 2007-01-01, 2007-01-01, 2007-01-…
#> $ company_id_cs <int32> 10830353, 10830353, 10830353, 10830353, 1083…
#> $ id_tie <int32> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 29…
#> $ exp_id_cs <double> 606461989, 606461989, 606461989, 606461989, …
#> $ member_id_cs <int32> 162, 162, 162, 162, 162, 162, 162, 162, 162,…
#> $ company_name_cs <string> "Kony, Inc.", "Kony, Inc.", "Kony, Inc.", "K…
#> $ title_cs <large_string> "Associate Engineer", "Associate Engineer", …
#> $ date_from_parsed_cs <date32[day]> 2015-06-01, 2015-06-01, 2015-06-01, 2015-06-…
#> $ date_to_parsed_cs <date32[day]> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
#> $ tjoin_tfound <double> 101, 101, 101, 101, 101, 101, 101, 101, 101,…
#> $ round_id <int32> 259195, 259196, 259197, 259198, 259199, 2592…
#> $ announced_on <date32[day]> 2011-02-24, 2011-03-01, 2011-06-07, 2012-01-…
#> $ raised_amount <double> 13370002, 8280000, 2352002, 2000000, 1500000…
#> $ before_join <bool> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TR…
#> Call `print()` for full schema detailsF2. How much capital has been acquired by the time the person joins?
F3. How many funding rounds have been acquired by the time the person joins?
# Initialize empty columns (not sure yet if that increases performance)
me_joined_unnested_dt[, `:=` (raised_amount_before_join = NA_real_,
num_rounds_before_join = NA_real_)]
# Add features
me_joined_unnested_dt[, `:=` (raised_amount_before_join = sum(raised_amount[before_join == T], na.rm = T),
num_rounds_before_join = sum( before_join[before_join == T])),
by = .(company_id, exp_id_cs)]
open_dataset("me_joined_unnested2.parquet") |>
glimpse()#> FileSystemDataset with 1 Parquet file
#> 88,429,236 rows x 17 columns
#> $ company_id_cbpb <int32> 85514, 85514, 85514, 85514, 85514, 85514, 8…
#> $ founded_on_cbpb <date32[day]> 2007-01-01, 2007-01-01, 2007-01-01, 2007-01…
#> $ company_id_cs <int32> 10830353, 10830353, 10830353, 10830353, 108…
#> $ id_tie <int32> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2…
#> $ exp_id_cs <double> 606461989, 606461989, 606461989, 606461989,…
#> $ member_id_cs <int32> 162, 162, 162, 162, 162, 162, 162, 162, 162…
#> $ company_name_cs <string> "Kony, Inc.", "Kony, Inc.", "Kony, Inc.", "…
#> $ title_cs <large_string> "Associate Engineer", "Associate Engineer",…
#> $ date_from_parsed_cs <date32[day]> 2015-06-01, 2015-06-01, 2015-06-01, 2015-06…
#> $ date_to_parsed_cs <date32[day]> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ tjoin_tfound <double> 101, 101, 101, 101, 101, 101, 101, 101, 101…
#> $ round_id <int32> 259195, 259196, 259197, 259198, 259199, 259…
#> $ announced_on <date32[day]> 2011-02-24, 2011-03-01, 2011-06-07, 2012-01…
#> $ raised_amount <double> 13370002, 8280000, 2352002, 2000000, 150000…
#> $ before_join <bool> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, T…
#> $ raised_amount_before_join <double> 120528113, 120528113, 120528113, 120528113,…
#> $ num_rounds_before_join <double> 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 5…
#> Call `print()` for full schema detailsNest again
# data.table
excluded_cols <- setdiff(names(me_joined_unnested_dt), c("round_id", "announced_on", "raised_amount", "before_join"))
me_joined_nested_dt <- me_joined_unnested_dt[, list(funding_rounds=list(.SD)), by=excluded_cols]
# Dplyr (not working)
# me_joined_nested_dt <- me_joined_unnested_dt |>
# nest(funding_rounds = c("round_id", "announced_on", "raised_amount", "before_join"))
open_dataset("me_joined_nested.parquet") |>
glimpse()#> FileSystemDataset with 1 Parquet file
#> 12,654,304 rows x 13 columns
#> $ company_id <int32> 71668, 5070, 117119, 5070, 117119, 7920, 52…
#> $ founded_on <date32[day]> 2019-01-01, 2014-07-01, 2015-01-01, 2014-07…
#> $ id_cs <int32> 23865165, 10861408, 10861408, 10861408, 108…
#> $ exp_id_cs <double> 1927546132, 1267852578, 1267852578, 2670635…
#> $ member_id_cs <int32> 1874511, 1874513, 1874513, 1874513, 1874513…
#> $ company_name_cs <string> "Three Good", "Point", "Point", "Point", "P…
#> $ title_cs <string> "Founder & CEO", "Customer Operations at Po…
#> $ date_from_parsed_cs <date32[day]> 2015-04-01, 2018-01-01, 2018-01-01, 2018-11…
#> $ date_to_parsed_cs <date32[day]> NA, NA, NA, NA, NA, NA, 2019-04-01, 2019-04…
#> $ tjoin_tfound <double> -45, 42, 36, 52, 46, 50, 105, -33, 49, 131,…
#> $ raised_amount_before_join <double> 0, 11399999, 12100000, 11399999, 12100000, …
#> $ num_rounds_before_join <double> 0, 2, 3, 2, 3, 6, 9, 0, 6, 9, 12, 7, 4, 9, …
#> $ funding_rounds <list<...>> [<tbl_df[5 x 4]>], [<tbl_df[5 x 4]>], [<tbl…
#> Call `print()` for full schema detailsTo differentiate between founder and non-founder CS titles are needed
# Prep data (shrink / remove unnecessary data)
me_joined_nested_foc_dt[, funding_rounds := NULL]
# Prep titles
me_wrangled_wt_dt <- me_dist_prqt |>
filter(company_id %in% cb_cs_joined_cs_ids, !is.na(date_from_parsed)) |>
select(exp_id_cs, title_cs) |>
collect() |>
setDT()
# Join
me_joined_nested_foc_dt[me_wrangled_wt_dt, on = .(exp_id_cs), title_cs := i.title_cs]
# Inspect
open_dataset("me_joined_nested_foc.parquet") |>
glimpse()#> FileSystemDataset with 1 Parquet file
#> 12,654,304 rows x 12 columns
#> $ company_id <int32> 71668, 5070, 117119, 5070, 117119, 7920, 52…
#> $ founded_on <date32[day]> 2019-01-01, 2014-07-01, 2015-01-01, 2014-07…
#> $ id_cs <int32> 23865165, 10861408, 10861408, 10861408, 108…
#> $ exp_id_cs <double> 1927546132, 1267852578, 1267852578, 2670635…
#> $ member_id_cs <int32> 1874511, 1874513, 1874513, 1874513, 1874513…
#> $ company_name_cs <string> "Three Good", "Point", "Point", "Point", "P…
#> $ title_cs <string> "Founder & CEO", "Customer Operations at Po…
#> $ date_from_parsed_cs <date32[day]> 2015-04-01, 2018-01-01, 2018-01-01, 2018-11…
#> $ date_to_parsed_cs <date32[day]> NA, NA, NA, NA, NA, NA, 2019-04-01, 2019-04…
#> $ tjoin_tfound <double> -45, 42, 36, 52, 46, 50, 105, -33, 49, 131,…
#> $ raised_amount_before_join <double> 0, 11399999, 12100000, 11399999, 12100000, …
#> $ num_rounds_before_join <double> 0, 2, 3, 2, 3, 6, 9, 0, 6, 9, 12, 7, 4, 9, …
#> Call `print()` for full schema detailsUnivariate summary statistics
Describing patterns found in univariate data
Plots
Separate between “Founder” & “Non-Founder” and calculate summary statistics necessary for plotting.
library(ggplot2)
lookup_term <- "founder"
data <- me_joined_nested_foc_prqt |>
filter(!is.na(title_cs)) |>
mutate(Role = title_cs |> tolower() |> str_detect(lookup_term)) |>
collect() |>
mutate(
Role = Role |> factor(levels = c(TRUE, FALSE),
labels = c('Founder', 'Non-Founder'))
)
# Summary Statistics (Mean & Median)
df_vline_long <- data |>
group_by(Role) |>
summarise(Mean = mean(tjoin_tfound), Median = median(tjoin_tfound), n = n()) |>
pivot_longer(c(Mean, Median,n ), names_to = "Statistic", values_to = "Value") |>
mutate(Value_chr = format(round(Value, 1), big.mark=".", decimal.mark = ",", drop0trailing = T),
gg_pos_y = rep(c(0.07,0.06, 0.05),2),
gg_color = rep(c("#8F8470", "#BF9240", "#FEA400"), 2))How many month have passed since the company was founded and before the person joined the company (binwidth: 3 months)?
data |>
# Plot
ggplot(aes(x = tjoin_tfound, fill = Role, color = Role)) +
geom_histogram(aes(y =..density..), size = .2, binwidth = 3, alpha = 0.5) +
facet_wrap(~Role, nrow=2) +
# Statistics & Design
ggnewscale::new_scale_color() +
geom_vline(data = df_vline_long |> filter(Statistic != "n"), aes(xintercept = Value, linetype = Statistic, color = Statistic), key_glyph = "path") +
scale_linetype_manual(values = c(2,3)) +
scale_color_manual(values = c("#8F8470", "#BF9240", "#FEA400")) +
geom_label(data = df_vline_long, aes(x = 100, y = gg_pos_y, label = paste0(Statistic, ' = ', Value_chr)),
color = df_vline_long$gg_color, fill = "transparent", alpha = 0.5, size = 3, hjust = "left") +
xlim(-250, 250) +
labs(x = "Δ T_join, T_foundation (in month)", y = "Density") +
theme(legend.key=element_blank())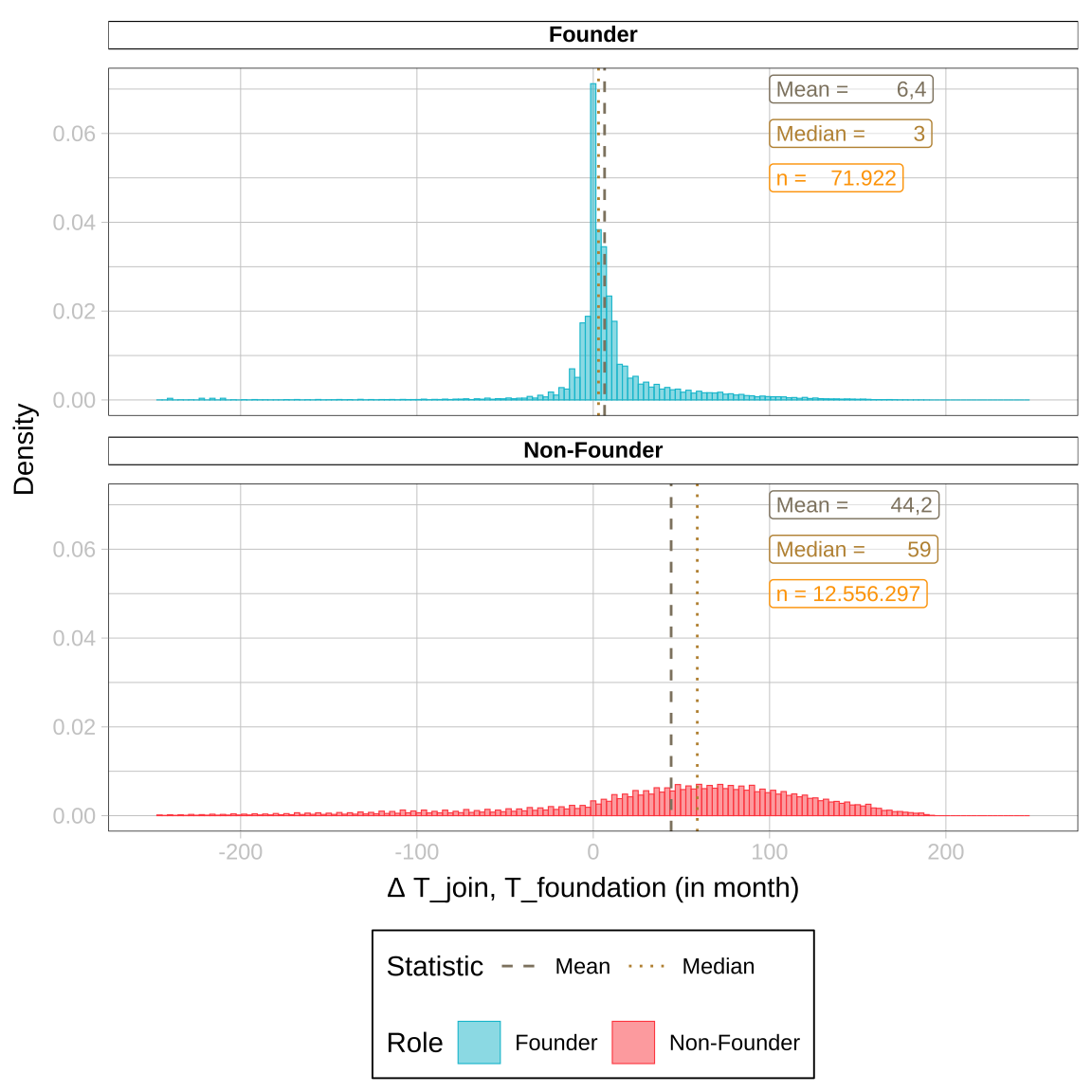
How much capital has been acquired by the time the person joins?
data |>
# Plot
ggplot(aes(x = raised_amount_before_join, color = Role, fill = Role)) +
geom_histogram(aes(y =..density..), alpha=0.5) +
facet_wrap(~Role, nrow=2) +
# Design
scale_x_continuous(labels = scales::label_number(prefix = "$", accuracy = 0.1, scale_cut = scales::cut_short_scale()), limits = c(NA,1e+09)) +
labs(x = "Raised amount before join", y = "Density", fill="", color = "")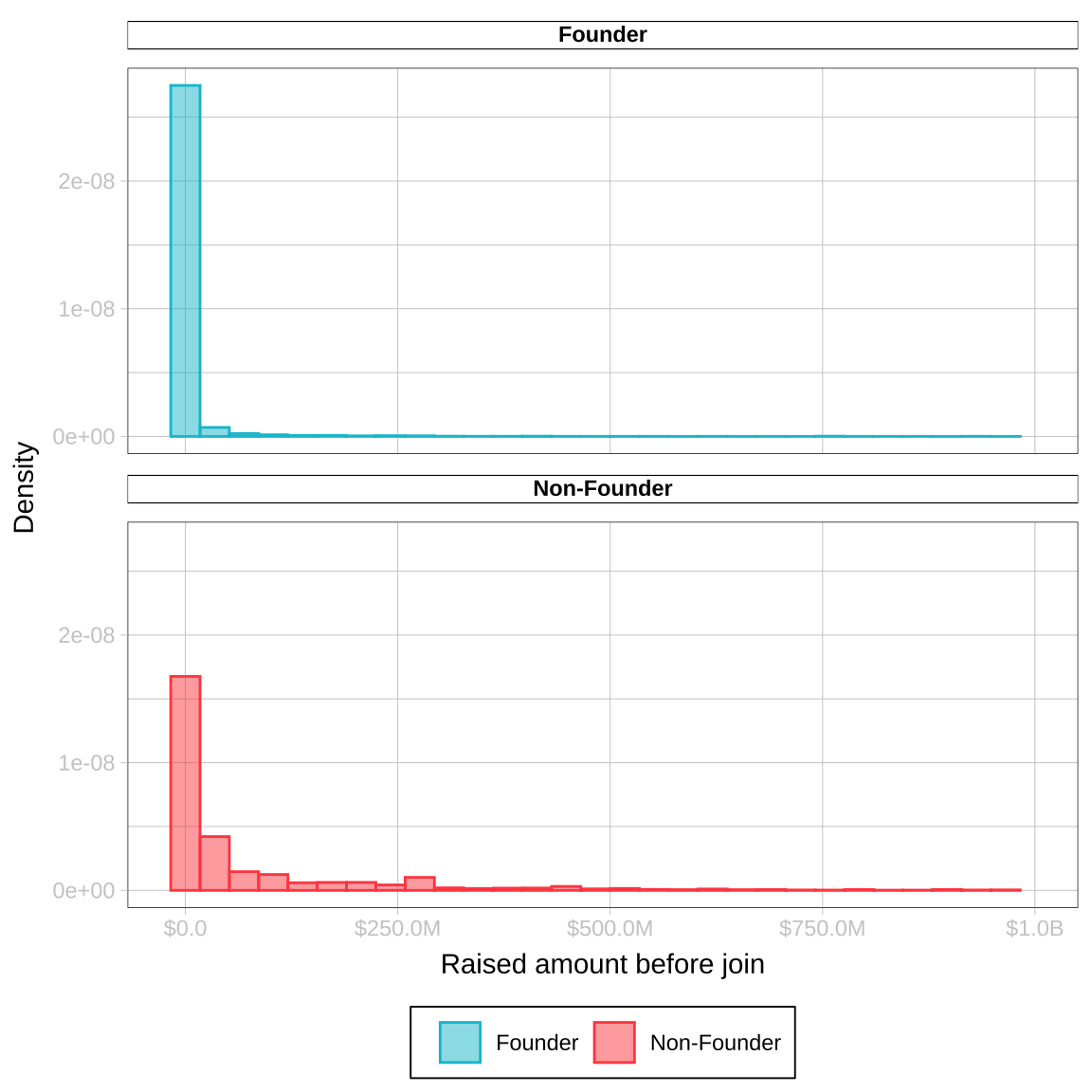
How many funding rounds have been acquired by the time the person joins?
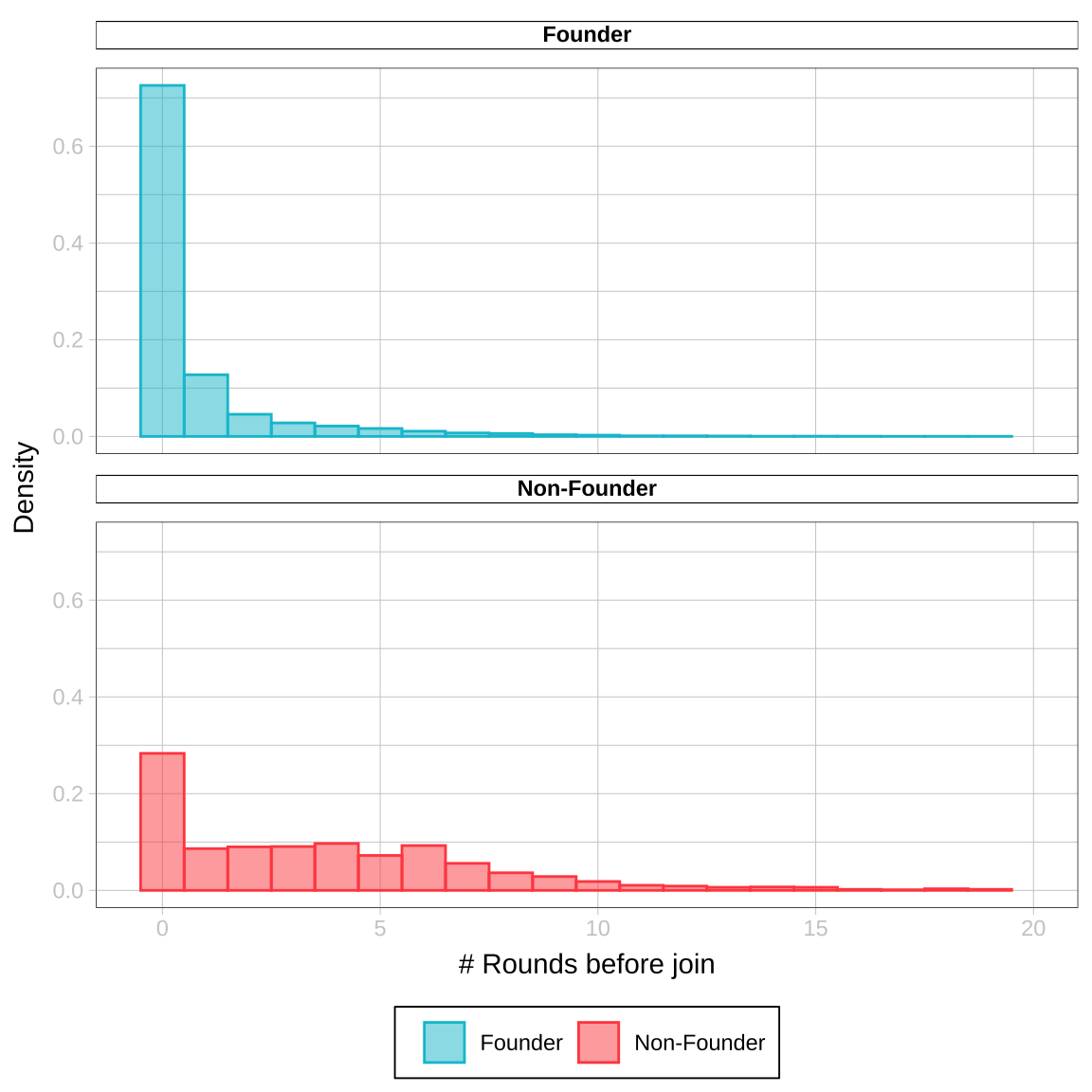
Fortune500
me_matched_members_dt <- me_matched_members_prqt |> collect()
# 46 Batches (Chunks with 5 Million rows)
slice_ids <- tibble(from = seq(1, 230000000, 5000000),to = c(seq(5000000, 225000000, 5000000), 229065592))
for (i in 1:46) {
# Build Batch
x <- slice_ids$from[i]; y <- slice_ids$to[i]
me_matched_members_slice_dt <- me_matched_members_dt[x:y,]
# Create Features
me_matched_members_slice_dt[, `:=` (f500 = (purrr::pmap_lgl(list(company_name, date_from_parsed, date_to_parsed), check_f500, .progress = TRUE)),
role = title |> tolower() |> stringr::str_detect("founder"))]
# Save
me_matched_members_slice_dt |> write_parquet(paste0("/media/tie/ssd2/joschka/me_f500/me_f500_", cur_id, ".parquet"))
}Employment History
Match current and past employments to corresponding Fortune500 companies
Employment History (Worked for Fortune 500 company?)
Content-related problems
- Matching problems:
- amd <> advanced micro devices
- intel <> intel corporation
- Geographical issues:
- Just US companies (use Fortune Global data)
Technical issues
Takes loooooooong time to calculate…
Code I (Data + Function)
Function
# 1. Function
check_f500 <- function(title, year_from, year_to) {
# Handle NA inputs
if (is.na(year_to)) {year_to <- 2023}
if (is.na(year_from)) {return(NA)}
# Filter time frame
data <- fortune500 |>
filter(year |> between(year_from, year_to)) |>
pull(company)
# Check match and return bool
title |> tolower() %in% data
}CoreSignal data (n = 229.065.592)
#> # A tibble: 6 × 7
#> id member_id company_id company_name title date_from_parsed date_to_parsed
#> <dbl> <int> <int> <chr> <chr> <date> <date>
#> 1 6.07e8 2605953 NA arkansas se… Corp… 2015-02-01 NA
#> 2 6.07e8 2605953 NA freelance m… Free… 2016-05-01 NA
#> 3 6.30e8 2605953 10415396 101 magazine Cont… 2012-08-01 2014-05-01
#> # ℹ 3 more rowsCode II (Chunkwise Execution)
# 1. Collect data
me_matched_members_dt <- me_matched_members_prqt |> collect()
# 2.Build batches
slice_ids <- tibble(
from = seq(1, 230000000, 5000000),
to = c(seq(5000000, 225000000, 5000000), 229065592),
)
for (i in 1:46) {
# Create current batch
x <- slice_ids$from[i]
y <- slice_ids$to[i]
me_matched_members_slice_dt <- me_matched_members_dt[x:y,]
# Add features
me_matched_members_slice_dt[, `:=` (f500 = (purrr::pmap_lgl(list(company_name, date_from_parsed, date_to_parsed), check_f500, .progress = TRUE)),
role = title |> tolower() |> stringr::str_detect("founder"))]
# Save
me_matched_members_slice_dt |> write_parquet(paste0("me_f500/me_f500_", cur_id, ".parquet"))
}Code III (Build feature)
# 1. Load data
me_f500 <- open_dataset("me_f500/") |>
collect()
# 2. Add Ids
me_dist_ids_prqt <- arrow::open_dataset("me_dist4.parquet") |> select(id, member_id) |> collect()
me_f500_id <- me_dist_ids_prqt[me_f500, on = .(id)]
# 3. Add features
# 3.1 Earliest founding date & earliest f500 date (if founded)
me_f500_id[,`:=` (founding_min = (ifelse(any(role == T), min(date_from_parsed[role==T]), NA_real_)),
f500_min_founding = (ifelse(any(role == T) & any(f500 == T), min(date_from_parsed[f500 == T]), NA_real_))),
by = .(member_id)]
# 3.2 Compare
me_f500_id[, f500_before_founding := f500_min_founding <= founding_min]Plot
Constraints:
- Analysis takes place on an annual level.
- First funding event is being considered
- Exact matches only
me_f500_id <- arrow::open_dataset("~/02_diss/01_coresignal/02_data/me_f500_id.parquet")
data <- me_f500_id |>
# Filter "Founder"
filter(role == T) |> collect()
data |>
ggplot(aes(x = f500_before_founding)) +
geom_bar() +
scale_x_discrete(labels=c("Employment at Fortune500\nAFTER\nfounding", "Employment at Fortune500\nBEFORE\nfounding", "Neither case")) +
scale_y_continuous(labels = scales::unit_format(unit = "M", scale = 1e-6, accuracy = 0.1)) +
labs(x = "", y = "Count")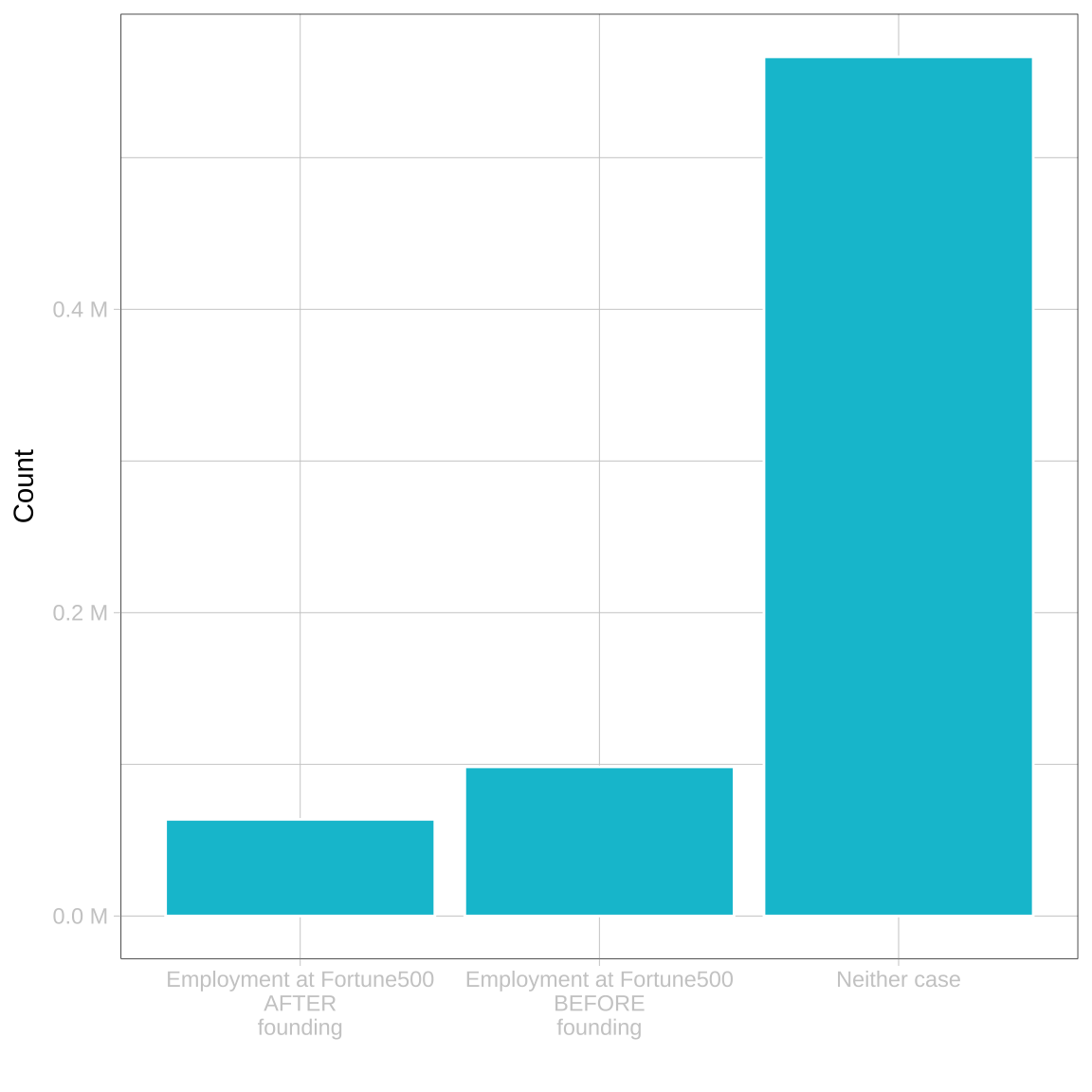
Employment Skills
Inferences from semantic similarity of LinkedIn users’ skills
Cluster skills
tbd
Current variables
Variables built from Experience, Education and funding data
Built variables
#> Rows: 2,659,657
#> Columns: 67
#> $ company_id_cbpb <int> 90591, 152845, 90440, 138208, 116…
#> $ funding_after_mid <chr> "yes", NA, "yes", "yes", "yes", "…
#> $ funding_after_early <chr> "yes", "no", "yes", "yes", "yes",…
#> $ member_id <int> 878, 2104, 3548, 3548, 3970, 4005…
#> $ id_tie <int> 38, 67, 89, 89, 96, 104, 183, 175…
#> $ exp_id_cs <dbl> 2481733250, 1423977093, 2638, 263…
#> $ exp_corporate <dbl> 0.00000, 12.00000, 0.00000, 0.000…
#> $ exp_funded_startup <dbl> 0, 0, 0, 0, 0, 0, 18, 0, 0, 0, 0,…
#> $ exp_founder <dbl> 0.0000, 0.0000, 0.0000, 0.0000, 0…
#> $ exp_f500 <dbl> 0.00000, 0.00000, 0.00000, 0.0000…
#> $ exp_research <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
#> $ exp_research_ivy <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
#> $ company_id_cs <int> 140537, 10644128, 6068905, 606890…
#> $ company_name_cs <chr> "Bristol-Myers Squibb", "HERE", "…
#> $ company_name_cbpb <chr> "receptos", "HERE Technologies Ch…
#> $ founded_on_cbpb <date> 2007-01-01, 2012-11-13, 2009-07-…
#> $ closed_on_cbpb <date> NA, NA, NA, NA, NA, NA, 2021-04-…
#> $ title_cs <chr> "Key Account Manager", "GIS Analy…
#> $ date_from_parsed_cs <date> 2006-01-01, 2016-01-01, 2010-01-…
#> $ date_to_parsed_cs <date> 2008-08-01, NA, NA, NA, 2011-10-…
#> $ tjoin_tfound <dbl> -12, 37, 6, 48, -47, 48, 17, 11, …
#> $ raised_amount_before_join_company <dbl> 0, 0, 0, 7722796, 0, 9961692, 333…
#> $ num_rounds_before_join <dbl> 0, 1, 0, 2, 0, 2, 1, 1, 2, 0, 1, …
#> $ is_f500 <lgl> TRUE, FALSE, TRUE, TRUE, FALSE, F…
#> $ is_founder <lgl> FALSE, FALSE, FALSE, FALSE, FALSE…
#> $ is_research <lgl> FALSE, FALSE, FALSE, FALSE, FALSE…
#> $ is_research_ivy <lgl> FALSE, FALSE, FALSE, FALSE, FALSE…
#> $ date_1st_founder_exp <date> NA, NA, NA, NA, NA, NA, NA, NA, …
#> $ date_1st_f500_exp <date> 2006-01-01, NA, 2010-01-01, 2010…
#> $ date_1st_funded_startup_exp <date> 2006-01-01, 2016-01-01, 2010-01-…
#> $ date_1st_research_exp <date> NA, NA, NA, NA, NA, NA, NA, NA, …
#> $ date_1st_research_ivy_exp <date> NA, NA, NA, NA, NA, NA, NA, NA, …
#> $ date_1st_corporate_exp <date> 2009-02-01, 2015-01-01, NA, NA, …
#> $ time_since_1st_corporate_exp <dbl> NA, 12, NA, NA, 116, NA, 136, 40,…
#> $ time_since_1st_founder_exp <dbl> NA, NA, NA, NA, NA, NA, NA, NA, N…
#> $ time_since_1st_f500_exp <dbl> NA, NA, NA, NA, NA, NA, NA, NA, N…
#> $ time_since_1st_funded_startup_exp <dbl> NA, NA, NA, NA, NA, NA, 96, NA, N…
#> $ time_since_1st_research_exp <dbl> NA, NA, NA, NA, NA, NA, NA, NA, N…
#> $ time_since_1st_research_ivy_exp <dbl> NA, NA, NA, NA, NA, NA, NA, NA, N…
#> $ time_since_1st_experience <dbl> 0, 12, 0, 0, 116, 0, 136, 40, 176…
#> $ raised_amount_before_founder_member <dbl> NA, NA, NA, NA, NA, NA, NA, NA, N…
#> $ raised_amount_before_all_member <dbl> NA, NA, NA, NA, NA, NA, 0, 0, NA,…
#> $ was_corporate_before <lgl> FALSE, TRUE, FALSE, FALSE, TRUE, …
#> $ was_founder_before <lgl> FALSE, FALSE, FALSE, FALSE, FALSE…
#> $ was_f500_before <lgl> FALSE, FALSE, FALSE, FALSE, FALSE…
#> $ was_fc_before <lgl> FALSE, FALSE, FALSE, FALSE, FALSE…
#> $ was_uni_before <lgl> FALSE, FALSE, FALSE, FALSE, FALSE…
#> $ was_ivy_before <lgl> FALSE, FALSE, FALSE, FALSE, FALSE…
#> $ stage_mid <lgl> NA, NA, NA, NA, NA, NA, NA, NA, N…
#> $ stage_late <lgl> NA, NA, NA, NA, NA, NA, FALSE, NA…
#> $ date_from_stage <chr> "early1", "mid", "early2", "mid",…
#> $ company_start_mid <date> 2009-01-01, 2014-11-13, 2011-07-…
#> $ company_start_late <date> 2009-11-23, 2017-11-13, 2014-07-…
#> $ rank_global_2023_best <int> 917, 1549, NA, NA, NA, NA, NA, NA…
#> $ score_global_2023_best <dbl> 40.6, 26.8, NA, NA, NA, NA, NA, N…
#> $ rank_national_2023_best <int> NA, NA, NA, NA, NA, NA, NA, NA, N…
#> $ rank_national_during_enrollment_best <int> NA, NA, NA, NA, NA, NA, NA, NA, N…
#> $ degree_ba2 <lgl> FALSE, TRUE, NA, NA, TRUE, NA, NA…
#> $ degree_ma2 <lgl> FALSE, FALSE, NA, NA, FALSE, NA, …
#> $ degree_phd2 <lgl> FALSE, FALSE, NA, NA, FALSE, NA, …
#> $ degree_mba2 <lgl> TRUE, FALSE, NA, NA, FALSE, NA, N…
#> $ num_rounds_cumulated_founder <int> NA, NA, NA, NA, NA, NA, NA, NA, N…
#> $ num_rounds_cumulated_all <int> NA, NA, NA, NA, NA, NA, 1, 1, NA,…
#> $ announced_on_sB <date> 2012-02-03, 2018-01-04, 2011-03-…
#> $ round_type_new_next <fct> Series C, Series C, Series C, Ser…
#> $ raised_amount_cumsum_sB <dbl> 46043054, 0, 1905000, 11022796, 2…
#> $ raised_amount_cumsum_sB_next <dbl> 76043054, 0, 8712306, 13854868, 4…cs_me_dist8_unest_wedu_dt |>
select(id_tie, member_id, exp_id_cs, company_id_cbpb, company_name_cbpb, company_id_cs, company_name_cs,
founded_on_cbpb, closed_on_cbpb,
title_cs) |>
glimpse()#> Rows: 2,659,657
#> Columns: 10
#> $ id_tie <int> 38, 67, 89, 89, 96, 104, 183, 175, 209, 243, 321, 37…
#> $ member_id <int> 878, 2104, 3548, 3548, 3970, 4005, 4224, 4224, 4317,…
#> $ exp_id_cs <dbl> 2481733250, 1423977093, 2638, 2638, 1736317868, 3084…
#> $ company_id_cbpb <int> 90591, 152845, 90440, 138208, 116099, 97810, 40123, …
#> $ company_name_cbpb <chr> "receptos", "HERE Technologies Chicago", "crowdtwist…
#> $ company_id_cs <int> 140537, 10644128, 6068905, 6068905, 11825305, 194148…
#> $ company_name_cs <chr> "Bristol-Myers Squibb", "HERE", "Oracle", "Oracle", …
#> $ founded_on_cbpb <date> 2007-01-01, 2012-11-13, 2009-07-01, 2006-01-01, 201…
#> $ closed_on_cbpb <date> NA, NA, NA, NA, NA, NA, 2021-04-09, NA, NA, NA, NA,…
#> $ title_cs <chr> "Key Account Manager", "GIS Analyst I", "QA", "QA", …cs_me_dist8_unest_wedu_dt |>
select(date_from_parsed_cs, date_to_parsed_cs,
tjoin_tfound, raised_amount_before_join_company, num_rounds_before_join) |>
glimpse()#> Rows: 2,659,657
#> Columns: 5
#> $ date_from_parsed_cs <date> 2006-01-01, 2016-01-01, 2010-01-01,…
#> $ date_to_parsed_cs <date> 2008-08-01, NA, NA, NA, 2011-10-01,…
#> $ tjoin_tfound <dbl> -12, 37, 6, 48, -47, 48, 17, 11, 44,…
#> $ raised_amount_before_join_company <dbl> 0, 0, 0, 7722796, 0, 9961692, 333333…
#> $ num_rounds_before_join <dbl> 0, 1, 0, 2, 0, 2, 1, 1, 2, 0, 1, 2, …#> Rows: 2,659,657
#> Columns: 10
#> $ is_f500 <lgl> TRUE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, FAL…
#> $ is_founder <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, …
#> $ is_research <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, …
#> $ is_research_ivy <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, …
#> $ was_corporate_before <lgl> FALSE, TRUE, FALSE, FALSE, TRUE, FALSE, TRUE, TRU…
#> $ was_founder_before <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, …
#> $ was_f500_before <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, …
#> $ was_fc_before <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, F…
#> $ was_uni_before <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, …
#> $ was_ivy_before <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, …cs_me_dist8_unest_wedu_dt |>
select(
starts_with("date_1st_"),
starts_with("time_since_1st_"),
starts_with("exp_"), -exp_id_cs) |>
glimpse()#> Rows: 2,659,657
#> Columns: 19
#> $ date_1st_founder_exp <date> NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ date_1st_f500_exp <date> 2006-01-01, NA, 2010-01-01, 2010-01…
#> $ date_1st_funded_startup_exp <date> 2006-01-01, 2016-01-01, 2010-01-01,…
#> $ date_1st_research_exp <date> NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ date_1st_research_ivy_exp <date> NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ date_1st_corporate_exp <date> 2009-02-01, 2015-01-01, NA, NA, 200…
#> $ time_since_1st_corporate_exp <dbl> NA, 12, NA, NA, 116, NA, 136, 40, 17…
#> $ time_since_1st_founder_exp <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, …
#> $ time_since_1st_f500_exp <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, …
#> $ time_since_1st_funded_startup_exp <dbl> NA, NA, NA, NA, NA, NA, 96, NA, NA, …
#> $ time_since_1st_research_exp <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, …
#> $ time_since_1st_research_ivy_exp <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, …
#> $ time_since_1st_experience <dbl> 0, 12, 0, 0, 116, 0, 136, 40, 176, 4…
#> $ exp_corporate <dbl> 0.00000, 12.00000, 0.00000, 0.00000,…
#> $ exp_funded_startup <dbl> 0, 0, 0, 0, 0, 0, 18, 0, 0, 0, 0, 0,…
#> $ exp_founder <dbl> 0.0000, 0.0000, 0.0000, 0.0000, 0.00…
#> $ exp_f500 <dbl> 0.00000, 0.00000, 0.00000, 0.00000, …
#> $ exp_research <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
#> $ exp_research_ivy <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …cs_me_dist8_unest_wedu_dt |>
select(score_global_2023_best,
starts_with("rank"),
starts_with("degree")) |>
glimpse()#> Rows: 2,659,657
#> Columns: 8
#> $ score_global_2023_best <dbl> 40.6, 26.8, NA, NA, NA, NA, NA, N…
#> $ rank_global_2023_best <int> 917, 1549, NA, NA, NA, NA, NA, NA…
#> $ rank_national_2023_best <int> NA, NA, NA, NA, NA, NA, NA, NA, N…
#> $ rank_national_during_enrollment_best <int> NA, NA, NA, NA, NA, NA, NA, NA, N…
#> $ degree_ba2 <lgl> FALSE, TRUE, NA, NA, TRUE, NA, NA…
#> $ degree_ma2 <lgl> FALSE, FALSE, NA, NA, FALSE, NA, …
#> $ degree_phd2 <lgl> FALSE, FALSE, NA, NA, FALSE, NA, …
#> $ degree_mba2 <lgl> TRUE, FALSE, NA, NA, FALSE, NA, N…cs_me_dist8_unest_wedu_dt |>
select(date_from_stage, company_start_mid, company_start_late,
raised_amount_before_founder_member, raised_amount_before_all_member,
funding_after_mid, funding_after_early) |>
glimpse()#> Rows: 2,659,657
#> Columns: 7
#> $ date_from_stage <chr> "early1", "mid", "early2", "mid", …
#> $ company_start_mid <date> 2009-01-01, 2014-11-13, 2011-07-0…
#> $ company_start_late <date> 2009-11-23, 2017-11-13, 2014-07-0…
#> $ raised_amount_before_founder_member <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA…
#> $ raised_amount_before_all_member <dbl> NA, NA, NA, NA, NA, NA, 0, 0, NA, …
#> $ funding_after_mid <chr> "yes", NA, "yes", "yes", "yes", "y…
#> $ funding_after_early <chr> "yes", "no", "yes", "yes", "yes", …Next Steps
Further analysis is necessary
- Match employment history with Fortune500 (revenue based selection)
- Cluster job titles
- Cluster skills
